




EXPLAIN¶
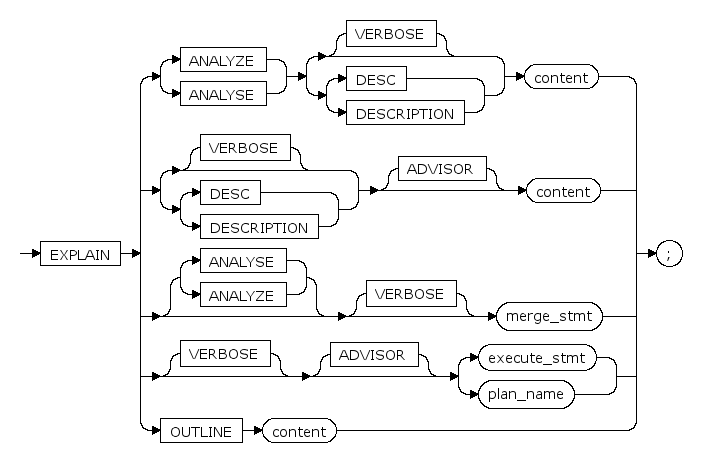
参数¶
ADVISOR
执行索引推荐功能,执行该选项后会显示推荐的索引及其计划。
相关细节可以查看 索引管理章节。
ANALYZE/ANALYSE
指定该关键字时,执行该命令并显示实际运行时间和其他统计数据。
VERBOSE
显示关于该计划的其他信息。具体而言,包括计划树中每个节点的字段列表,模式识别表和函数名称。
用范围表别名标记表达式中的变量。
merge_stmt
MERGE 语句(合并两个基本表或视图)请参见 MERGE。
execute_stmt
EXECUTE 语句(执行查询计划)请参见 EXECUTE。
plan_name
执行计划名称。
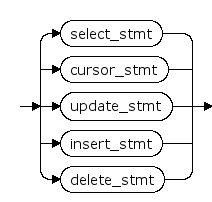
select_stmt
SELECT 语句(在数据库中进行数据检索)请参见 SELECT。
cursor_stmt
DECLARE 语句(定义游标)请参见 DECLARE。
update_stmt
UPDATE 语句(更新一个基本表或视图中的一行或多行)请参见 UPDATE。
insert_stmt
INSERT 语句(向一个基本表或视图中插入数据)请参见 INSERT。
delete_stmt
DELETE 语句(从一个基本表或视图中删除数据)请参见 DELETE。
OUTLINE
展示固定计划所需的Hint组
注解
EXPLAIN的结果形象地表示了执行器执行查询的步骤,这包括如下几点:
- 查询中只有单张表时,以什么方式扫描该表,顺序扫描还是使用索引扫描
- 当查询中涉及到多张表时,以什么顺序访问这些表,对这些表使用什么方式进行联接( NestLoop Join 、 MergeJoin 、 HashJoin ),联接时哪张表作外表,哪张表作内表,对各张单个表使用什么方式扫描。
- 除了上述信息外,EXPLAIN还会把执行每一步的启动代价和总代价显示出来。当使用索引时,还会指出使用哪一列上的索引,索引扫描时扫描键是什么,过滤条件是什么。
- 加上ANALYZE后,还可以了解执行器执行查询的时间。
了解EXPLAIN提供的这些信息有助于理解神通数据库中优化器的行为,从而帮助用户通过建立索引或更改查询语句来控制查询优化器使之生成理想的执行计划,达到提高应用程序执行性能的目的。
注解
不同数据库版本的查询出来的执行计划中cost、rows和width等值可能不同
示例1:EXPLAIN¶
cost表示了此执行计划代价,前面为启动代价,为0.00;后面为总代价,为89.92。rows和width分别表示优化器根据统计信息得到的对查询结果有多少行和每行的平均宽度的估计值:
-- 清理环境
DROP TABLE tab CASCADE;
-- 创建表
CREATE TABLE tab(a int);
EXPLAIN SELECT * FROM tab;
QUERY PLAN
-------------------------------------------------------
Seq Scan on TAB (cost=0.00..89.92 rows=8192 width=4)
(1 row)
-- 删除
DROP TABLE tab CASCADE;
示例2:EXPLAIN ANALYZE¶
actual time表示了后台实际执行的代价,rows和width分别表示实际查询结果有多少行和每行的平均宽度,当ANALYZE存在时表示实际执行一次所获得的各项统计值:
-- 清理环境
DROP TABLE tab CASCADE;
-- 创建表
CREATE TABLE tab(a int);
EXPLAIN ANALYZE SELECT * FROM tab;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Seq Scan on TAB (cost=0.00..89.92 rows=8192 width=4) (actual time=0.01..0.01 rows=0 loops=1)
Planning Time: 0.08 msec
Execution Time: 0.06 msec
(3 rows)
-- 删除
DROP TABLE tab CASCADE;
示例3:EXPLAIN VERBOSE¶
VERBOSE详细显示了查询计划树上的各个节点信息:
-- 清理环境
DROP TABLE tab CASCADE;
--创建表
CREATE TABLE tab(a int);
EXPLAIN VERBOSE SELECT * FROM tab;
QUERY PLAN
-------------------------------------------------------
{ SEQSCAN
:startup_cost 0.00
:total_cost 89.92
:rows 8192
:width 4
:qptargetlist (
{ TARGETENTRY
:resdom
{ RESDOM
:resno 1
:restype 23
:restypmod -1
:resname A
:reskey 0
:reskeyop 0
:ressortgroupref 0
:resjunk false
}
:expr
{ VAR
:varno 1
:varattno 1
:vartype 23
:vartypmod -1
:varlevelsup 0
:varnoold 1
:varoattno 1
}
:bNoCheckForRead false
:bNoCheckForWrite false
:isnotnull false
}
)
:qpreturningList <>
:qpqual <>
:lefttree <>
:righttree <>
:extprm ()
:locprm ()
:initplan <>
:nprm 0
:scanrelid 1
:scan_key <>
:scan_filter <>
}
Seq Scan on TAB (cost=0.00..89.92 rows=8192 width=4)
(52 rows)
--删除
DROP TABLE tab CASCADE;
示例4:EXPLAIN ADVISOR¶
ADVISOR显示数据库推荐的索引以及使用推荐索引后的执行计划:
-- 清理环境
DROP TABLE tab CASCADE;
--创建表
CREATE TABLE tab(a int, b int);
EXPLAIN ADVISOR SELECT * FROM tab WHERE a < 3 or b < 5;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------
Seq Scan on TAB (cost=0.00..130.88 rows=4551 width=8)
Scan Filter: ((A < 3) OR (B < 5))
Advise Index: CREATE INDEX ADV_IDX_TAB_A ON SYSDBA.TAB(A);
Advise Index: CREATE INDEX ADV_IDX_TAB_B ON SYSDBA.TAB(B);
New Query Plan:
Index Scan using ADV_IDX_TAB_A(Normal Index Scan), ADV_IDX_TAB_B(Normal Index Scan) on TAB (cost=0.03..111.45 rows=4551 width=8)
Index Key: ((A < 3) OR (B < 5))
Index Filter: (TRUE OR TRUE)
(10 rows)
--删除
DROP TABLE tab CASCADE;
注解
- 可通过ADVISOR_INDEX_MAX_WIDTH参数限制索引组合的列数。该参数范围为[1, 8],默认值为4。
示例5:EXPLAIN OUTLINE¶
Outline区域显示了固定当前计划所需的Hint组
-- 清理环境
drop table t1 cascade;
drop table t2 cascade;
drop index idx1;
-- 创建表和索引
create table t1(a int);
create table t2(a int);
create index idx1 on t1(a);
explain outline select * from t1,(select * from t2 where t2.a = 1) where t1.a = 1;
QUERY PLAN
--------------------------------------------------------------------------------------
Nested Loop(Inner Join) (cost=0.00..261.57 rows=10602 width=8)
-> Index Scan using IDX2(Fast Index Scan) on T2 (cost=0.00..1.01 rows=1 width=4)
Index Key: (A = 1)
-> Seq Scan on T1 (cost=0.00..154.54 rows=10602 width=4)
Scan Key: (A = 1)
Outline
-------
INDEX(@SEL$1 SYSDBA.T2@SEL$2 IDX2)
FULL(@SEL$1 SYSDBA.T1@SEL$1)
USE_NL(@SEL$1 (SYSDBA.T2@SEL$2),(SYSDBA.T1@SEL$1))
(13 rows)
-- 清理环境
drop table t1
drop table t2