




CREATE TABLE¶
说明¶
创建新表
语法¶
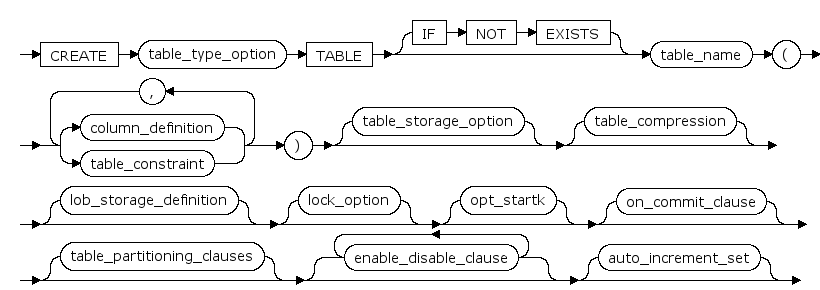
create_table ::=


constraint_state ::=
table_constraint ::=
use_index_option ::=

key_actions ::=
action ::=
opt_startk ::=

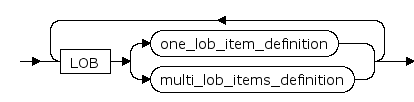
multi_lob_items_definition ::=


lob_parameters ::=
table_partitioning_clauses ::=
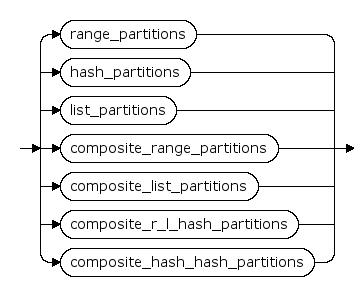
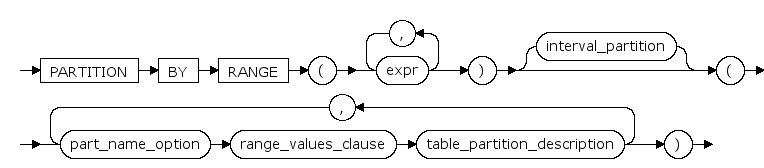
range_partitions ::=

part_name_option ::=
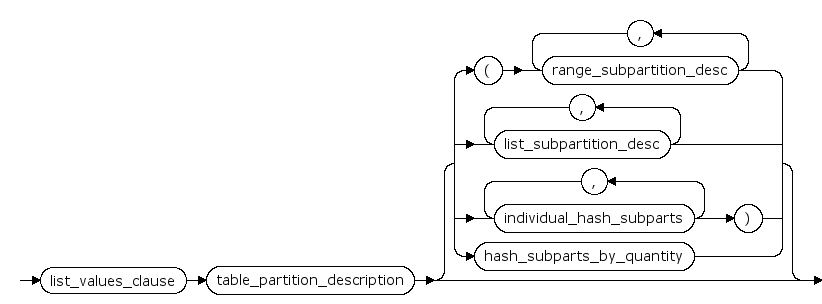
list_partitions ::=

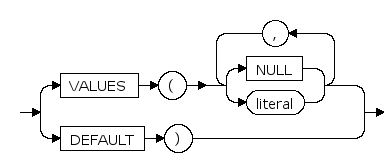
hash_partitions ::=

individual_hash_partitions ::=


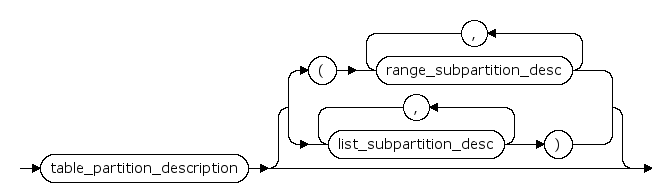
table_partition_description ::=

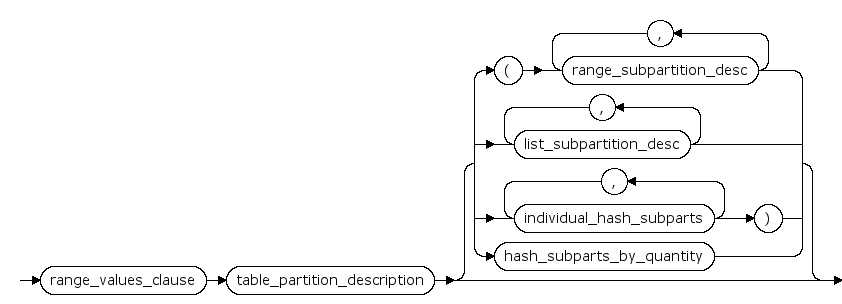
composite_range_partitions ::=
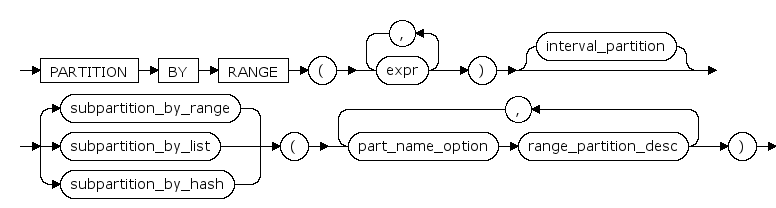
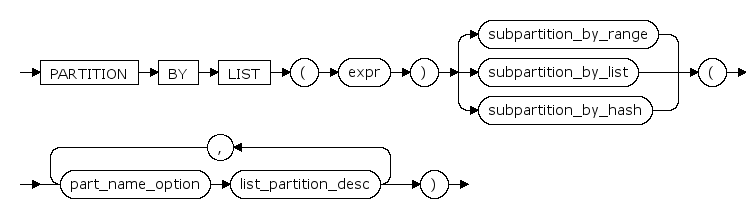
composite_r_l_hash_partitions ::=
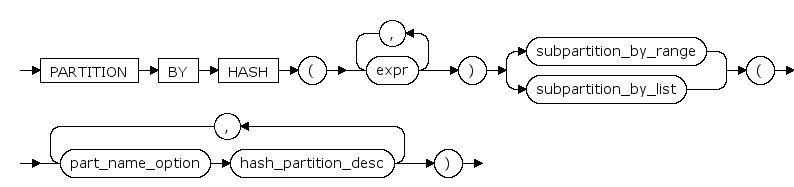
composite_hash_hash_partitions ::=





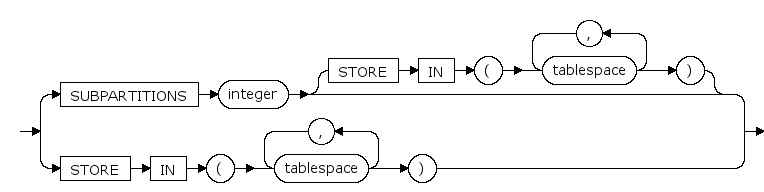
subpartition_by_hash_template ::=

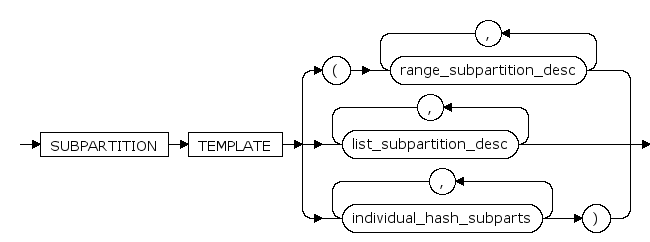



encrypt_option ::=
full_encryption ::=

storage_clause ::=
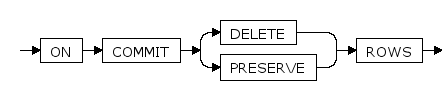
on_commit_clause ::=
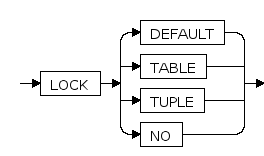
lock_option ::=
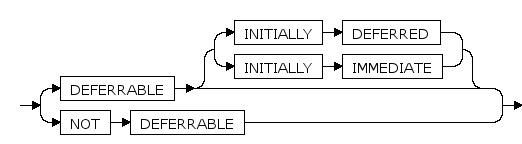
defer_option ::=

参数¶
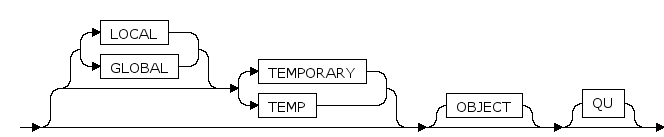
[ LOCAL | GLOBAL ] { TEMPORARY | TEMP }
如果声明了此参数,则该表创建为临时表。
当指定LOCAL或忽略时表示本地临时表,本地临时表仅在当前会话中可见。
注解
虽然可以通过指定模式名的方式来访问其它会话的局部临时表数据,但请不要这么做, 以免出现数据丢失的情况,因为局部临时表在会话结束后将被销毁。
当指定GLOBAL时表示临时表定义在所有有权限的会话可中都可见,临时表中的数据只有向表中插入数据的会话可见。临时表分为事务级临时表和会话级临时表,可以通过ON COMMIT选项指定创建何种类型的临时表, 不指定时默认为事务级临时表 。会话级临时表中数据的生命周期为整个会话连接时间内,事务级临时表中数据的生命周期为当前事务内。
当开启兼容 SQL Server 参数后。默认为会话级临时表。
注解
神通数据库中sql语句默认处于事务内,所以使用事务级临时表时需要显式开启事务。
OBJECT
如果声明了此参数,则该表自动创建一个数据类型,该数据类型代表对应该表一行的元组类型(结构类型).因此,这时表不能和一个现有数据类型同名.
QU
如果声明此参数,则该表被定义为快速更新表,快速更新表的存储比较特殊,它不使用压缩,并且预留了将来所需要的所有的空间,每一行的存储结构都一样。快速更新表是为了提高全表更新某一个属性的性能而出现的,快速更新表可以调用ACI的快速更新接口进行更新。快速更新表必须指定主键,否则无法进行快速更新。快速更新会一次性接收所有的数据(包括主键值和要更新的值),然后根据主键值找到更新的数据进行更新。
注解
可能有的后台不支持此语法,这是因为此后台还没有快速更新功能
快速更新表不支持垂直分区
快速更新动作不维护更新属性上的索引,所以不要在快速更新属性上建立索引,或者需要用户来维护快速更新属性上的索引
快速更新动作不做任何约束检查,所以用户需求确定更新数据是否满足约束要求
IF NOT EXISTS
当不存在一个同名的关系时会创建表,否则不会创建表,且会打印NOTICE提示信息
table_name
要创建的表的名字,表名必须符合标识符规则。同一模式下,表、索引、视图、序列不能同名。
LOCK { DEFAULT | TABLE | TUPLE | NO}
建议执行过程加锁模式。
DEFAULT建议由执行过程自动决定
TABLE建议执行过程对表级锁, 不加行锁.
TUPLE建议执行过程对表加意向锁,对具体操作的元组加行级锁
NO建议执行过程对表不加锁.
如果不指定LOCK选项, 默认为LOCK DEFAULT. 一般情况下应该使用LOCK DEFAULT选项,LOCK TABLE可以减少加锁数量,降低加锁开销,但可能降低并发度.LOCK TUPLE有利于提高并发度,但会增加加锁数量,增加加锁开销..
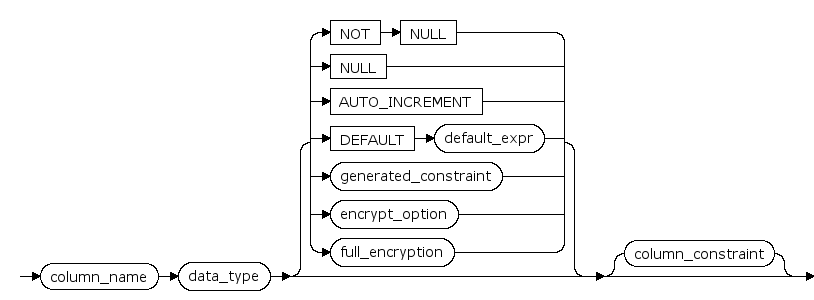
column_name
是表中的列名。列名必须符合标识符规则,并且在表内唯一。
data_type
该字段的数据类型声明
NULL | NOT NULL
是确定列中是否允许空值的关键字。从严格意义上讲,NULL 不是约束,但可以使用与指定 NOT NULL 同样的方法指定。
AUTO_INCREMENT
指定AUTO_INCREMENT关键字,声明列为自增列。
一个表中至多只有一列为自增列,且自增列数据类型必须为整型或者浮点类型。
自增列必须有单独的PRIMARY KEY或UNIQUE,即自增列不能没有约束或者仅有组合约束(多列约束)。
向自增列插入时,插入 NULL、DEFAULT、0或不指定值,均插入内部自增的NEXT值
注解
神通的自增列,主要兼容 MySQL5.7 及之前版本的表现。
DEFAULT default_expr
子句给它所出现的字段一个缺省数值.该数值可以是任何不含变量的表达式(不允许使用子查询和对本表中的其它字段的交叉引用).缺省表达式的数据类型必须和字段类型匹配.
[ GENERATED ALWAYS ] AS ( generated_expr ) [ VIRTUAL | STORED ]
声明列为生成列,其中 VIRTUAL 或 缺省关键字用于声明虚拟列,STORED 关键字用于声明存储列。
- 生成列是可以通过指定表达式 generated_expr (可引用其他列中的数据)来计算取值的列。
- 生成列分为虚拟列、存储列(在神通数据库中,虚拟列与存储列除了语法、属性信息不同外,在实际效果上没有差异)。
在以下场景中可以考虑使用生成列:
- 使用虚拟列简化和统一查询。比如:将复杂的查询条件定义成一个生成列,然后在查询该表时使用,从而确保所有的查询都使用相同的判断条件。
- 使用存储列减少查询时的计算成本。比如:存储列作为查询条件的物化缓存(materialized cache)。
- 使用生成列模拟函数索引。比如:定义一个基于函数表达式的生成列并在该列上创建索引。
注解
- 生成列取值表达式 generated_expr 禁止依赖生成列。
- 生成列取值表达式 generated_expr 禁止依赖大对象列。
- 大对象列禁止声明为生成列。
- 行前触发器读取生成列的 :new 值为插入、更新的新值(即根据 generated_expr 表达式计算得到的值)。
- 允许直接直接插入或更新生成列,但插入或更新的值没有意义,生成列取值仍然是根据 generated_expr 表达式计算得到的。
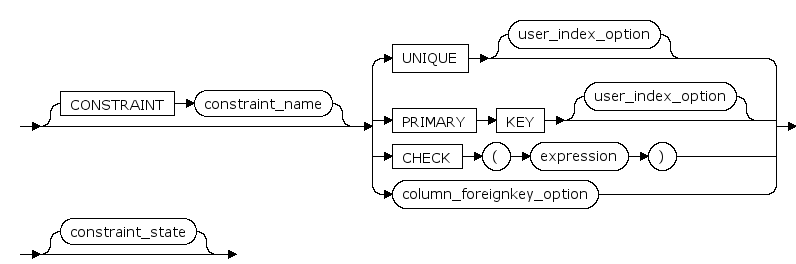
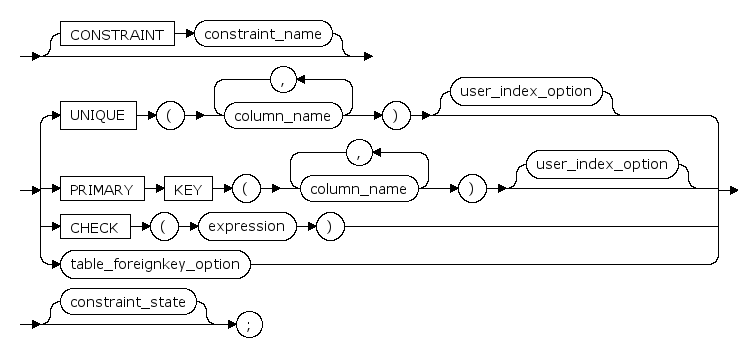
CONSTRAINT constraint_name
列或表约束的可选名字.如果没有声明,则由系统生成一个名字.
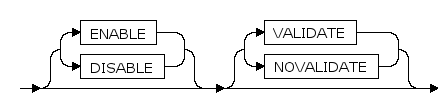
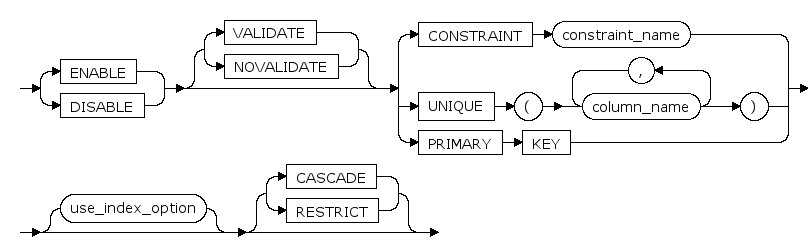
ENABLE | DISABLE
指定ENABLE选项,启用约束,约束将应用于表中的数据。
指定DISABLE选项可以禁用完整性约束。
如果ENABLE一个UNIQUE或PRIMARY KEY,将会创建索引。
不能ENABLE一个引用了DISABLE状态的唯一键或主键的FOREIGN KEY。
默认是ENABLE。
VALIDATE | NOVALIDATE
是否对已有的数据进行约束检查。
VALIDATE和NOVALIDATE的行为依赖于约束是ENABLE还是DISABLE,
如果指定了ENABLE,但没有指定VALIDATE与NOVALIDATE,默认是VALIDATE。
如果指定了DISABLE,但没有指定VALIDATE与NOVALIDATE,默认是NOVALIDATE。
UNIQUE
是通过唯一索引为给定的一列或多列提供实体完整性的约束。一个表可以有多个 UNIQUE 约束。
PRIMARY KEY
是通过唯一索引对给定的一列或多列强制实体完整性的约束。对于每个表只能创建一个 PRIMARY KEY 约束。
USING INDEX index_name
建表时, 当表具有UNIQUE或PRIMAY KEY约束时, 可以指定创建的唯一性索引的名字
CHECK (expression)
是通过限制可输入到一列或多列中的可能值强制域完整性的约束。
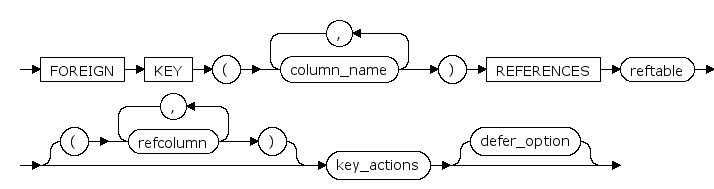
REFERENCES | FOREIGN KEY...REFERENCES
是为列中的数据提供引用完整性的约束。FOREIGN KEY 约束要求列中的每个值在被引用表中对应的被引用列中都存在。FOREIGN KEY 约束只能引用被引用表中为 PRIMARY KEY 或 UNIQUE 约束的列或被引用表中在 UNIQUE INDEX 内引用的列。
reftable
是 FOREIGN KEY 约束所引用的表名。
( refcolumn ) | ( refcolumn [, ... ] )
是 FOREIGN KEY 约束所引用的表中的一列或多列。
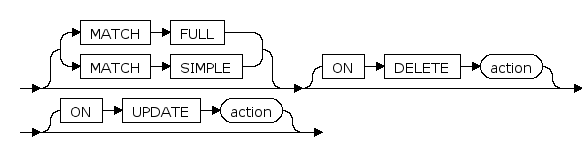
MATCH FULL
向这些列增加的数值将使用给出的匹配类型与参考表的参考列中的数值进行匹配,不允许一个多字段外键的字段为NULL
ON DELETE
指定当要创建的表中的行具有引用关系,并且从父表中删除该行所引用的行时,要对该行采取的操作。
ON UPDATE
指定当要创建的表中的行具有引用关系,并且在父表中更新该行所引用的行时,要对该行采取的操作。
DEFERRABLE | NOT DEFERRABLE
这两个关键字设置该约束是否可推迟.一个不可推迟的约束将在每条命令之后马上检查.可以推迟的约束检查可以推迟到事务结尾. 目前只有外键约束接受这个子句.所有其它约束类型都是不可推迟的.
缺省是 NOT DEFERRABLE。
INITIALLY IMMEDIATE | INITIALLY DEFERRED
如果约束是可推迟的,那么这个子句声明检查约束的缺省时间.如果约束是 INITIALLY IMMEDIATE,那么每条语句之后就检查它.这个是缺省.如果约束是 INITIALLY DEFERRED,那么只有在事务结尾才检查它.
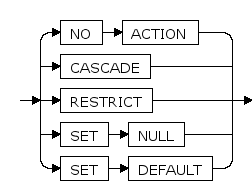
action
- NO ACTION表示删除或者更新将产生一个违反外键约束的动作,生成错误,它是缺省动作。
- RESTRICT对应atction 的一个选项,与NO ACTION 相同。禁用约束时,仅当没有其它约束依赖于该约束时,才会禁用约束。
- CASCADE对应action 的一个选项,删除任何引用了被删除行的行,或者分别把引用行的字段值更新为被参考字段的新数值。
- SET NULL把引用行数值设置为 NULL。
- SET DEFAULT把引用列的数值设置为它们的缺省值。
默认为NO ACTION
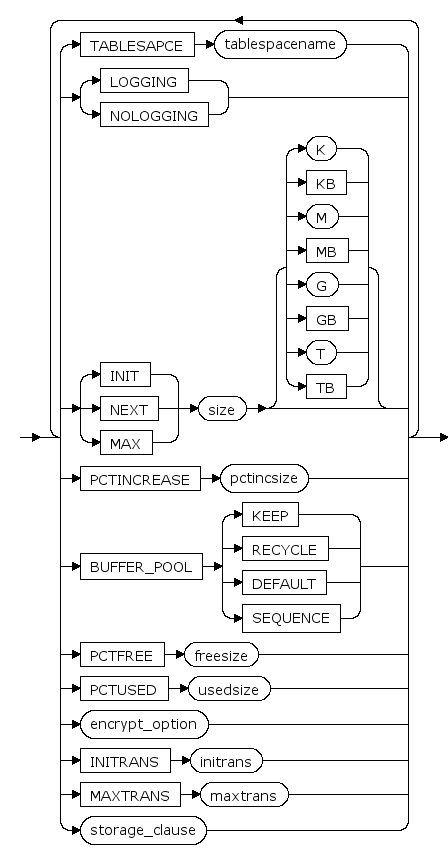
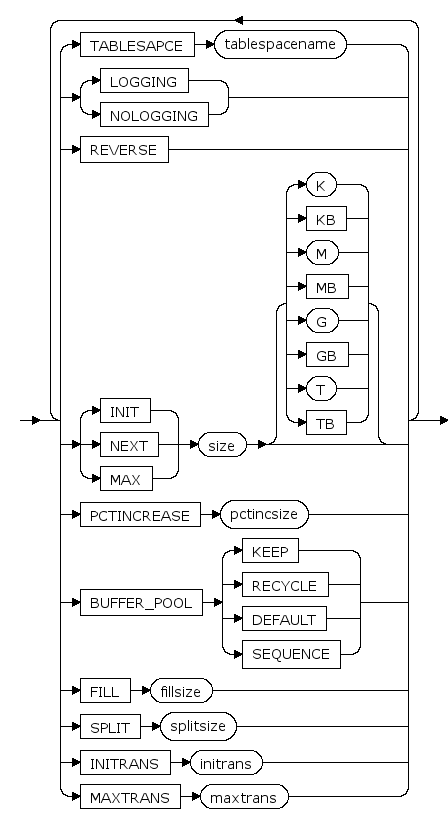
TABLESPACE tablespacename
表空间名
LOGGING | NOLOGGING
对表进行的操作记日志或不记日志。
NOLOGGING可以使对象上的操作产生的日志量最少,通常指定NOLOGGING可以改善大数据量操作的性能,对少量数据的操作只有很小的影响,在大数据量NOLOGGING操作结束后应当将对象改回LOGGING模式。除以下操作外,不建议对其它操作使用NOLOGGING模式:
CREATE INDEX、ALTER INDEX REBUILD、INSERT INTO ... SELECT
大量的大对象数据操作
由于NOLOGGING模式下记录的少量日志无法满足数据库回滚和介质恢复的需要,你必须非常谨慎地使用这种模式,而且要与负责备份和恢复的人沟通之后才能使用。在执行NOLOGGING操作前应当为可能受影响的数据文件建立一个备份,一旦操作失败或发生事务回滚,必须从备份进行恢复,以避免产生数据不一致的情况。 执行NOLOGGING操作后,必须执行ALTER SYSTEM CHECKPOINT命令建立检查点强制数据刷新到磁盘上,并尽快为受影响的数据文件建立一个新的基准备份,从而避免由于介质失败而丢失对这些对象的后续修改。
对象之间的LOGGING属性是相互独立的,表与LOB字段、表与索引的LOGGING属性都不会互相影响。例如,如果想对索引在NOLOGGING模式下重建,只需执行ALTER INDEX ... REBUILD NOLOGGING. 并不需要对表进行NOLOGGING设置。
REVERSE
只有在访问方法为BTREE时可以使用此选项,标明此选项后BTREE将为倒序BTREE索引。
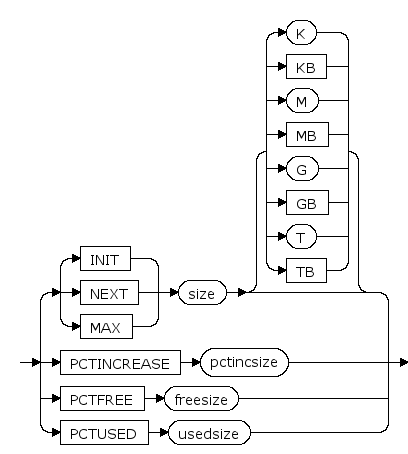
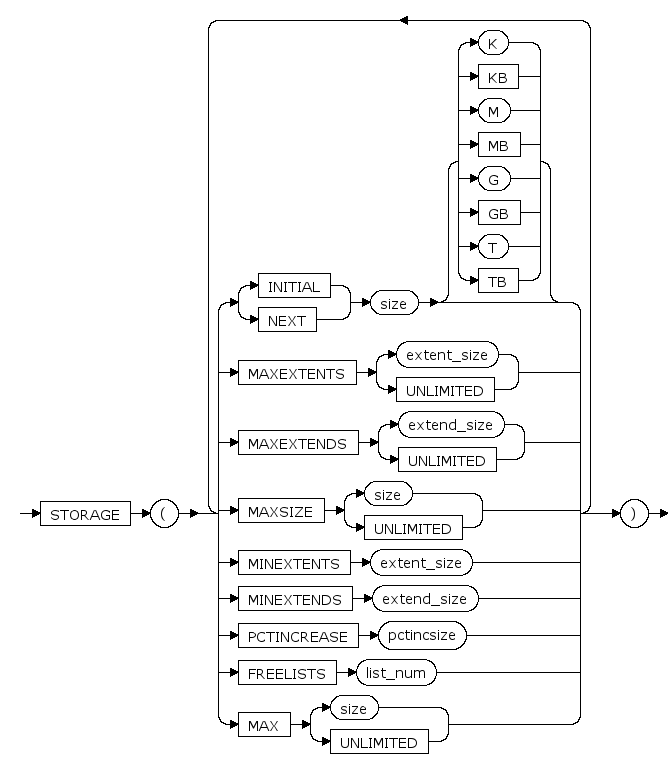
INIT size [ K | KB | M | MB | G | GB | T | TB ]
表空间大小的初始值, K,KB,M,MB,G,GB,T,TB分别是可选的字节单位
默认是M(兆字节)
NEXT size [ K | KB | M | MB | G | GB | T | TB ]
表空间大小的增长步长, K,KB,M,MB,G,GB,T,TB分别是可选的字节单位,增长步长为64k的倍数
默认是M(兆字节)
PCTINCREASE pctincsize
段增长步长的增长比例。每次段增长的大小为段当前大小的pctincsize%
表创建时如果未指定PCTINCREASE,表的PCTINCREASE属性将继承表空间的PCTINCREASE的值
注解
PCTINCREASE 和 NEXT (NEXT 属性值不允许为 0)之间扩展表空间大小的逻辑为:
- 当 PCTINCREASE 属性值不为 0 时,按照 PCTINCREASE 属性值来扩展,NEXT 属性值不生效
- 当 PCTINCREASE 属性值为 0 时,则按照 NEXT 属性值扩展
而且按照 PCTINCREASE 属性值增长时,每次增长大小内部会限定成最大 1G 。
MAX size [ K | KB | M | MB | G | GB | T | TB ]
表空间大小的最大值, K,KB,M,MB,G,GB,T,TB分别是可选的字节单位
默认是M(兆字节)
BUFFER_POOL {KEEP|RECYCLE|DEFAULT|SEQUENCE}
BUFFER_POOL子句用于为指定的模式对象指定一个默认的缓存方式。
- 指定KEEP,表示尽量将该模式对象数据缓存在内存中;
- 指定RECYCLE,表示采用LRU算法换出该模式对象数据;
- 指定SEQUENCE,表示按顺序换出该模式对象数据;
指定DEFAULT时,表示采用系统默认的缓存方式,当前系统默认缓存方式为RECYCLE。
PCTFREE freesize
保留空闲空间百分比,详见 sys_segment(段信息) 的 PCTFREE 列的说明
PCTUSED usedsize
恢复可插入的空间百分比,详见 sys_segment(段信息) 的 PCTUSED 列的说明
FILL fillsize
索引填充系数,详见 sys_segment(段信息) 的 PCTFREE 列的说明
SPLIT splitsize
索引分裂系数,详见 sys_segment(段信息) 的 PCTUSED 列的说明
INITRANS initrans
页面上的初始事务槽数。 当事务对页面进行首次更新操作时,需要先占用一个本页面里的事务槽。在此事务结束后,占用的事务槽才可被其它事务重新占用。 initrans取值范围是[1, maxtrans]。
不指定的话默认值是2
MAXTRANS maxtrans
页面上的事务槽扩展上限。 当页面的initrans事务槽不够用时,如果页面有空闲空间,可以自动进行事务槽的扩展,扩展到不超过maxtrans个事务槽。 maxtrans取值范围是[1, 255]。
不指定的话默认值是255
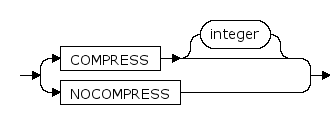
COMPRESS [integer] | NOCOMPRESS
- 指定COMPRESS,表示对表数据压缩存储。COMPRESS后跟integer以指定压缩等级;
- 指定NOCOMPRESS,表示表数据不压缩存储。
默认是NOCOMPRESS。
OVERFLOW START integer
指定OVERFLOW START integer对表数据垂直分区存储,OVERFLOW START后跟integer,指定从表的第几列开始垂直分区,列号从0开始。
表的继承受到表生存期的限制,生存期长的表不能继承生存期短的表。各种表的生存期关系是:正规表 全局临时表 局部临时表。也就是正规表不能继承全局临时表和局部临时表,全局临时表不能继承局部临时表。
lob_item
LOB列名
lob_segname
LOB列所在的段名,若不指定,则由系统自动生成;每个LOB列必须对应唯一的一个段
lob_parameters
LOB段的存储参数,若不指定,则使用与主表相同的存储参数
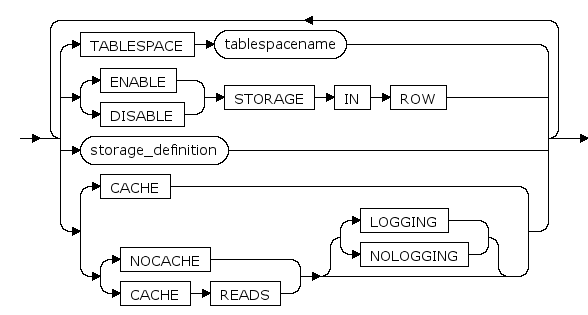
TABLESPACE tablespacename
该参数与此前的“TABLESPACE tablespacename”含义相同,此选项用于指定创建LOB列时LOB段所在的表空间。一般情况下,当LOB段与主表所在的段位于不同的表空间时,效率较高。每个LOB段在不同的表空间可以避免硬件设备的竞争,从而提高访问效率。
当用户未指定表空间,则LOB数据和索引均在主表的表空间内;
当用户指定了表空间,则LOB数据和索引均在指定的表空间内。
注解
存储位置还受参数 ENABLE|DISABLE STORAGE IN ROW 的影响。
ENABLE|DISABLE STORAGE IN ROW
是否允许小于等于600字节的LOB内容存储在行内。
ENABLE:允许小于等于600字节的数据存储在行内,默认值。
DISABLE:不管插入数据长度如何,系统将直接将数据存储在LOB段中。
CACHE
(暂不支持)缓存LOB页
CACHE READS
(暂不支持)读LOB时缓存,写LOB时不缓存
NOCACHE
(暂不支持)不缓存LOB页,缺省
LOGGING|NOLOGGING
该参数与此前的“LOGGING|NOLOGGIN”含义相同,此处针对于创建LOB段。选项仅在CACHE READS或NOCACHE时有效,当设置CACHE时,该选项必须为LOGGING;当设置CACHE READS或NOCACHE且未指定该属性时,该选项与LOB所在表空间的相应日志选项相同
storage_definition
LOB段的存储参数
INT size [ K | KB | M | MB | G | GB | T | TB ]
该参数与此前的“INT size [ K | KB | M | MB | G | GB | T | TB ]”相同,此处作用于创建LOB段。
NEXT size [ K | KB | M | MB | G | GB | T | TB ]
该参数与此前的“NEXT size [ K | KB | M | MB | G | GB | T | TB ]”相同,此处作用于创建LOB段。
MAX size [ K | KB | M | MB | G | GB | T | TB ]
该参数与此前的“MAX size [ K | KB | M | MB | G | GB | T | TB ]”相同,此处作用于创建LOB段。
PCTFREE freesize
该参数与此前的“PCTFREE freesize”相同,此处作用于创建LOB段。
PCTUSED usedsize
该参数与此前的“PCTUSED usedsize”相同,此处作用于创建LOB段。
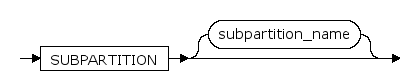
PARTITION partition_name
定义分区的名字。
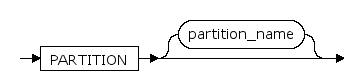
PARTITION ... MAXVALUE
分区值的最大值,用户可以为最大分区定义一个 MAXVALUE 修饰符。MAXVALUE 代表一个无穷大值,用于识别大于所有可能分区键的数据(包括 null)。
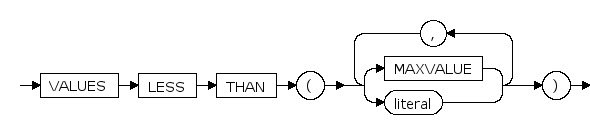
PARTITION ... DEFAULT
标识list分区中用户未指定的所有分区值。
PARTITION ... NULL
标识list分区中某分区包含空值。
PARTITION ... literal
与分区键类型匹配的常值。
PARTITION ... hash_partition_quantity
该参数为定义hash分区时,分区的数目。
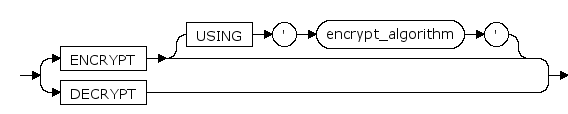
ENCRYPT | DECRYPT
设置表或列的加密模式。
ENCRYPT 设置表或列为加密模式,数据将会加密存储。
DECRYPT 设置为表或列非加密模式,数据不会被加密。
缺省时,表的加密模式将保持与表空间的加密模式一致。属性的加密模式不与表的加密模式一致,缺省时是不加密的
注解
属性加密目前语法只支持使用ENCRYPT,不支持使用USING子句。
USING 'encrypt_algorithm'
指定加密算法。目前支持的加密算法包括:'des3' 、 'aes128' 、 'aes192' 、 'aes256'、 'sm4'。
COLUMN_ENCRYPTION_KEY = 'cek_name'
指定CEK名字
ENCRYPTION_TYPE = 'encryption_type'
指定加密方式,目前仅支持 DETERMINISTIC(确定性加密)
ALGORITHM = 'algorithm'
指定加密列的加密算法,以字符串格式输入
ON COMMIT DELETE|PRESERVE ROWS
ON COMMIT选项只有在创建全局临时表时才有效,用于指定全局临时表的数据是会话隔离还是事务隔离。
DELETE ROWS:指定全局临时表为事务级临时表,即数据是事务隔离的,在事务提交/回滚时会截断临时表,删除临时表中的所有行。
PRESERVE ROWS:指定全局临时表为会话级临时表,即数据是会话隔离的,在会话结束时会截断临时表,删除临时表中的所有行。
当不指定ON COMMIT选项时,临时表默认为事务级临时表。
PARTITION ... expr
分区键返回类型,不可以是以下类型,ROWID, LONG, LOB, XMLType, 或者TIMESTAMP 的TIMEZONE。
individual_hash_partitions
这个clause用于申请分区表,且可以指定每一个哈希分区表的存储属性。
partitioning_storage_clause
partitioning_storage_clause中只能定义分区表的tablespace与表的压缩属性。
hash_part_by_quantity
这个clause用户申请多个子分区表,且所有的子分区表的存储属性都相同。子分区表的名称是系统自动生成的。
PARTITION ... tablespacename
用户可以指定一个或多个tablespace, tablespace的个数可以小于子分区表的个数,这时多出的分区表会以第一个tablespace为起点,循环分配到tablespace中。这只在分区表创建中有效,当分区表创建完毕,添加分区表时,将按正常的继承关系继承tablespace。(注:与oracle不同,oracle在创建过后此语句依然有效)
subpartition_by_hash
创建哈希-哈希复合分区时不能指定此clause中的SUBPARTITIONS interger
auto_increment_set
建表时设置自增列的起始序列值。
注解
每个表最多可以有 2500 列。表的行数及总大小仅受可用存储空间的限制。每行最多可以存储 8106 字节(除大对象类型BLOB和CLOB)。如果创建具有 varchar或 varbinary 列的表,并且列的字节总数超过 8106 字节,虽然仍可以创建此表,但会出现警告信息。如果试图插入超过 8106 字节的行或对行进行更新以至字节总数超过 8106,将出现错误信息并且语句执行失败。
可以创建本地和全局临时表。本地临时表仅在当前会话中可见;全局临时表在所有会话中都可见。除非使用 DROP TABLE 语句显式除去临时表,否则本地临时表将在当前会话结束时由系统自动除去.全局临时表在系统重新启动时自动除去。临时表可以方便用户,用户不需要关注表的删除.临时表可以不记日志,提高性能.
可以创建事务级临时表和会话级临时表。临时表的定义对所有有权限的会话可见,各个会话临时表中的数据是相互隔离的。临时表需要记录日志,以支持事务级临时表的回滚等操作。事务级临时表的数据在事务提交或回滚时会被截断,会话级临时表的数据在会话结束时会被截断。临时表不会自动删除,只能在没有其他会话绑定时使用 DROP TABLE 语句显示删除。
临时表的创建与普通表的创建基本一致,有如下不同:
- 当临时表被创建时只在系统表中保存元数据,不创建数据段,每一个会话第一次向临时表中插入数据时会创建一个与会话相关联的数据段,即临时表的实例化(通过视图v_sys_temp_instance可以查看当前所有的临时表实例),此时临时表与该会话绑定,在会话结束时销毁数据段并解除绑定,事务级临时表rollback仅回滚数据不回滚(删除)数据段实例,当有其他会话与临时表绑定时无法删除临时表。
- 全局临时表不支持外键约束,支持指定存储参数,但不支持指定初始大小、表空间和nologging;本地临时表没有限制。
- 临时表不支持分区、并行、统计信息、导入和全文索引。
一个表只能包含一个 PRIMARY KEY 约束。在 PRIMARY KEY 约束中定义的所有列都必须定义为 NOT NULL。每个 UNIQUE 约束都生成一个索引。如果在 FOREIGN KEY 约束的列中输入非 NULL 值,则此值必须在被引用的列中存在,否则将返回违反外键约束的错误信息。FOREIGN KEY 可以引用同一表中的其它列(自引用)。列级 FOREIGN KEY 约束的 REFERENCES 子句仅能列出一个引用列,且该列必须与定义约束的列具有相同的数据类型。表级 FOREIGN KEY 约束的 REFERENCES 子句中引用列的数目必须与约束列列表中的列数相同。每个引用列的数据类型也必须与列表中相应列的数据类型相同。FOREIGN KEY 约束只能引用被引用表的 PRIMARY KEY 或 UNIQUE 约束中的列或被引用表上 UNIQUE INDEX 中的列。
每个表系统都会创建两个系统属性:bigint类型的ROWID和smallint类型的SYSATTR_ROWVERSION。ROWID是表的一个元组的唯一标识符。SYSATTR_ROWVERSION表示元组修改的版本号,初始版本号是随机生成的,每次对元组做一次UPDATE操作,SYSATTR_ROWVERSION自动加1。
多次定义外键,将导致服务器按定义顺序依次触发外键检查动作。
NULL约束会被NOT NULL约束和Primary Key约束覆盖。
如果在创建含有LOB属性列的表时,对LOB属性列重复指定LOB存储参数,则第一次指定的参数有效。
表可以是分区表,提供基本的range、list、hash分区。对于range、hash分区,支持单列、多列;list只支持单列。在创建分区表时可以指定每个分区的名字、存储属性和LOB属性等。
INITIAL size [ K | KB | M | MB | G | GB | T | TB ]
表空间大小的初始值, K,KB,M,MB,G,GB,T,TB分别是可选的字节单位,默认是M(兆字节)
{MAXEXTENTS | MINEXTENTS} extent_size
该参数用于指定创建segment时分配的extent数。
FREELISTS list_num
该参数用于指定freelist的个数。
示例¶
示例1: 创建表(带有约束)
-- 清理环境
DROP TABLE tab1 CASCADE;
DROP TABLE tab2 CASCADE;
DROP TABLE tab3 CASCADE;
-- 带有 NOT NULL 、 UNIQUE 约束
CREATE TABLE tab1
(
a CHAR(3) NOT NULL UNIQUE,
b CHAR(20),
c CHAR(6),
d DECIMAL(9),
e CHAR(15)
);
-- 带有外键、主键约束
CREATE TABLE tab2
(
aa CHAR(3) NOT NULL,
bb CHAR(3) NOT NULL REFERENCES tab1(a),
cc DECIMAL(5),
PRIMARY KEY (aa, cc)
);
-- 带有 DEFAULT 、 CHECK 约束
CREATE TABLE tab3
(
aaa CHAR(30) NOT NULL UNIQUE,
bbb CHAR(20) DEFAULT 'Bill',
ccc DECIMAL(4) CHECK(ccc > 3),
ddd CHAR(15)
);
-- 删除表
DROP TABLE tab3;
DROP TABLE tab2;
DROP TABLE tab1;
示例2: 创建表(使用 LOCK 选项)
-- 清理环境
DROP TABLE tab2 CASCADE;
-- 建议执行模块对表操作加表级锁
CREATE TABLE tab2 (a CHAR(3), b CHAR(20)) LOCK TABLE;
-- 删除表
DROP TABLE tab2;
示例3: 创建表(使用 LOB 选项)
-- 清理环境
DROP TABLE tab3 CASCADE;
DROP TABLE tab4 CASCADE;
DROP TABLE tab5 CASCADE;
DROP TABLESPACE test;
CREATE TABLESPACE test DATAFILE 'testdbf.dbf';
-- 含有 1 个 LOB 类型属性列
-- 不指定 LOB 列任何参数
CREATE TABLE tab3 (a INT, b BLOB);
-- 含有 2 个 LOB 类型属性列
-- 两个LOB列分别存储在两个不同的LOB段中, 段名由系统指定,两个LOB列共享存储参数
CREATE TABLE tab4 (a INT, b BLOB, c BLOB)
LOB(b, c) STORE AS (TABLESPACE users ENABLE STORAGE IN ROW CACHE);
-- 含有 2 个 LOB 类型属性列
-- 分别指定其 LOB 段名等参数
CREATE TABLE tab5 (a INT, b BLOB, c CLOB)
LOB(b) STORE AS lobsegname1
LOB(c) STORE AS lobsegname2(TABLESPACE test DISABLE STORAGE IN ROW NOCACHE LOGGING);
-- 清理环境
DROP TABLE tab3;
DROP TABLE tab4;
DROP TABLE tab5;
DROP TABLESPACE test;
示例4: 创建表(禁用/启用约束)
-- 清理环境
DROP TABLE tab4 CASCADE;
-- 禁用/启用约束
CREATE TABLE tab4
(
id INT,
a CHAR(3),
b VARCHAR(30),
c INT CHECK(c < 55),
PRIMARY KEY(id, a),
UNIQUE(b)
) DISABLE PRIMARY KEY DISABLE NOVALIDATE UNIQUE(b);
-- 删除表
DROP TABLE tab4;
示例5: 指定表缓存方式、表压缩、垂直分区
-- 清理环境
DROP TABLE tab5 CASCADE;
-- 指定表缓存方式、表压缩、垂直分区
CREATE TABLE tab5 (a INT, b INT)
INIT 2M NEXT 2M BUFFER_POOL KEEP
COMPRESS 10
OVERFLOW START 1;
-- 删除表
DROP TABLE tab5;
示例6: 使用 ON COMMIT 选项
-- 清理环境
DROP TABLE tab6 CASCADE;
DROP TABLE tab7 CASCADE;
DROP TABLE tab8 CASCADE;
-- 创建事务级临时表
CREATE GLOBAL TEMPORARY TABLE tab6(a INT, b VARCHAR(10));
-- 创建事务级临时表
CREATE GLOBAL TEMPORARY TABLE tab7(a int, b varchar(10)) ON COMMIT DELETE ROWS;
-- 创建会话级临时表
CREATE GLOBAL TEMPORARY TABLE tab8(a int, b varchar(10)) ON COMMIT PRESERVE ROWS;
-- 删除表
DROP TABLE tab6;
DROP TABLE tab7;
DROP TABLE tab8;
示例7: 创建 RANGE 分区表
-- 清理环境
DROP TABLE tab7 CASCADE;
-- 创建 RANGE 分区表
CREATE TABLE tab7 (id INT, a INT, b VARCHAR(20))
PARTITION BY RANGE (a)
(
PARTITION t7_p1 VALUES LESS THAN (100),
PARTITION t7_p2 VALUES LESS THAN (200),
PARTITION t7_p3 VALUES LESS THAN (300),
PARTITION t7_p4 VALUES LESS THAN (MAXVALUE)
);
-- 删除表
DROP TABLE tab7;
示例8: 创建 HASH 分区表
-- 清理环境
DROP TABLESPACE ts1;
DROP TABLESPACE ts2;
DROP TABLESPACE ts3;
DROP TABLESPACE ts4;
DROP TABLE tab8 CASCADE;
DROP TABLE tab9 CASCADE;
DROP TABLE tab10 CASCADE;
DROP TABLE tab11 CASCADE;
-- 创建 HASH 分区表(不指定分区名, 不指定表空间)
CREATE TABLE tab8 (id INT, a INT, b VARCHAR(20))
PARTITION BY HASH (a) PARTITIONS 4;
-- 创建 HASH 分区表(指定分区名, 不指定表空间)
CREATE TABLE tab9 (id INT, a INT, b VARCHAR(20))
PARTITION BY HASH (a)
(
PARTITION t9_p1,
PARTITION t9_p2,
PARTITION t9_p3,
PARTITION t9_p4
);
-- 创建表空间
CREATE TABLESPACE ts1 DATAFILE 'ts1.dt' SIZE 5M AUTOEXTEND ON NEXT 5M;
CREATE TABLESPACE ts2 DATAFILE 'ts2.dt' SIZE 5M AUTOEXTEND ON NEXT 5M;
CREATE TABLESPACE ts3 DATAFILE 'ts3.dt' SIZE 5M AUTOEXTEND ON NEXT 5M;
CREATE TABLESPACE ts4 DATAFILE 'ts4.dt' SIZE 5M AUTOEXTEND ON NEXT 5M;
-- 创建 HASH 分区表(不指定分区名, 指定表空间)
CREATE TABLE tab10 (id INT, a INT, b VARCHAR(20))
PARTITION BY HASH (a) PARTITIONS 4
STORE IN (ts1, ts2, ts3, ts4);
-- 创建 HASH 分区表(指定分区名, 部分指定表空间)
CREATE TABLE tab11 (id INT, a INT, b VARCHAR(20))
PARTITION BY HASH (a)
(
PARTITION t11_p1 TABLESPACE ts1,
PARTITION t11_p2,
PARTITION t11_p3 TABLESPACE ts3,
PARTITION t11_p4
);
-- 删除表
DROP TABLE tab8;
DROP TABLE tab9;
DROP TABLE tab10;
DROP TABLE tab11;
DROP TABLESPACE ts1;
DROP TABLESPACE ts2;
DROP TABLESPACE ts3;
DROP TABLESPACE ts4;
示例9: 创建 LIST 分区表
-- 清理环境
DROP TABLE tab9 CASCADE;
-- 创建 LIST 分区表
CREATE TABLE tab9 (a INT, b CHAR(10), c INT, d VARCHAR(20))
PARTITION BY LIST (a)
(
PARTITION t9_p1 VALUES (1, 3, 5, 7, 9),
PARTITION t9_p2 VALUES (2, 4, 6, 8, 10),
PARTITION t9_p3 VALUES (DEFAULT)
);
-- 删除表
DROP TABLE tab9;
示例10: 创建复合分区表(以 RANGE-LIST 复合分区表为例)
-- 清理环境
DROP TABLE tab10 CASCADE;
DROP TABLE tab11 CASCADE;
-- 创建 LIST 分区表(使用分区模版)
CREATE TABLE tab10 (id INT, a DATE, b INT)
PARTITION BY RANGE (a)
SUBPARTITION BY LIST (b)
SUBPARTITION template
(
SUBPARTITION t10_sp1 VALUES (1),
SUBPARTITION t10_sp2 VALUES (DEFAULT)
)
(
PARTITION t10_p1 VALUES LESS THAN ('2005-1-1'),
PARTITION t10_p2 VALUES LESS THAN ('2006-1-1'),
PARTITION t10_p3 VALUES LESS THAN ('2007-1-1')
);
-- 创建 LIST 分区表(不使用分区模版)
CREATE TABLE tab11 (id INT, a DATE, b INT)
PARTITION BY RANGE (a)
SUBPARTITION BY LIST (b)
(
PARTITION t11_p1 VALUES LESS THAN ('2005-1-1')
(
SUBPARTITION t11_sp1 VALUES (1),
SUBPARTITION t11_sp2 VALUES (DEFAULT)
),
PARTITION t11_p2 VALUES LESS THAN ('2006-1-1')
(
SUBPARTITION t11_sp3 VALUES (1),
SUBPARTITION t11_sp4 VALUES (2),
SUBPARTITION t11_sp5 VALUES (3)
),
PARTITION t11_p3 VALUES LESS THAN ('2007-1-1')
(
SUBPARTITION t11_sp6 VALUES (DEFAULT)
)
);
-- 删除表
DROP TABLE tab10;
DROP TABLE tab11;
示例11: 创建间隔分区表
-- 清理环境
DROP TABLE tab11 CASCADE;
DROP TABLE tab12 CASCADE;
-- 创建间隔分区表
CREATE TABLE tab11(a DATE, b INT, c VARCHAR(20))
PARTITION BY RANGE (a)
INTERVAL(NUMTOYMINTERVAL (1, 'MONTH'))
(
PARTITION t11_p1 VALUES LESS THAN ('2005-1-1'),
PARTITION t11_p2 VALUES LESS THAN ('2006-1-1'),
PARTITION t11_p3 VALUES LESS THAN ('2007-1-1')
);
-- 创建 间隔 - HASH 复合分区表
CREATE TABLE tab12 (a DATE, b NUMBER)
PARTITION BY RANGE (a) INTERVAL (NUMTOYMINTERVAL (1, 'MONTH'))
SUBPARTITION BY hash(b)
SUBPARTITION template
(
SUBPARTITION p1,
SUBPARTITION p2,
SUBPARTITION p3,
SUBPARTITION P4
)
(
PARTITION t12_p1 VALUES LESS THAN ('2005-1-1'),
PARTITION t12_p2 VALUES LESS THAN ('2006-1-1'),
PARTITION t12_p3 VALUES LESS THAN ('2007-1-1')
);
-- 删除表
DROP TABLE tab11;
DROP TABLE tab12;
示例12: 创建有自增列的表
-- 清理环境
DROP TABLE tab12;
-- 整型列指定为自增列
-- 唯一约束列指定为自增列
CREATE TABLE tab12(id INT AUTO_INCREMENT UNIQUE, b INT);
INSERT INTO tab12 VALUES(NULL, 1);
INSERT INTO tab12(b) VALUES(2);
INSERT INTO tab12 VALUES(0, 3),(DEFAULT, 3),(NULL, 5);
SELECT * FROM tab12 ORDER BY b;
ID(int) |B(int) |
-------------------------
1 |1 |
-------------------------
2 |2 |
-------------------------
3 |3 |
-------------------------
4 |3 |
-------------------------
5 |5 |
总数目:5
DROP TABLE tab12;
-- 浮点型列指定为自增列
-- 主键列指定为自增列
CREATE TABLE tab12(id FLOAT AUTO_INCREMENT, b INT, PRIMARY KEY(id));
DROP TABLE tab12;
-- 多列主键的部分列指定为自增列
CREATE TABLE tab12(id INT AUTO_INCREMENT, b INT, PRIMARY KEY(id, b));
DROP TABLE tab12;
-- 不支持除整型或浮点型外的其他数据类型自增列
CREATE TABLE tab12(id CHAR AUTO_INCREMENT UNIQUE, b INT);
ERROR, 自增列(AUTO_INCREMENT)的数据类型应该使用整型或浮点类型
-- 不支持多列自增列
CREATE TABLE tab12(id INT AUTO_INCREMENT UNIQUE, b INT, c INT AUTO_INCREMENT UNIQUE);
ERROR, 表只能有一列自增列
示例13: 创建有生成列的表
-- 清理环境
DROP TABLE tab13;
-- 创建带有生成列的表
-- 使用缺省、VIRTUAL 关键字声明虚拟列
-- 使用 STORED 关键字声明存储列
CREATE TABLE tab13(u1 INT, r1 INT, r2 INT, g1 INT GENERATED ALWAYS AS (r1 + r2), g2 INT GENERATED ALWAYS AS (r1 - r2) VIRTUAL, g3 INT GENERATED ALWAYS AS (r2 - r1) STORED);
-- 插入数据(指定非生成列值)
INSERT INTO tab13(u1, r1, r2) VALUES(1, 10, 11);
-- 插入数据(指定部分生成列值)
INSERT INTO tab13(u1, r1, r2, g2) VALUES(2, 20, 21, 201);
-- 插入数据(指定全部生成列值)
INSERT INTO tab13(u1, r1, r2, g1, g2, g3) VALUES(3, 30, 31, 300, 301, 302);
SELECT * FROM tab13 ORDER BY u1;
U1(int) |R1(int) |R2(int) |G1(int) |G2(int) |G3(int) |
------------------------------------------------------------------------------
1 |10 |11 |21 |-1 |1 |
------------------------------------------------------------------------------
2 |20 |21 |41 |-1 |1 |
------------------------------------------------------------------------------
3 |30 |31 |61 |-1 |1 |
总数目:3
-- 更新数据(非生成列的依赖列)
UPDATE tab13 SET u1 = u1 + 1000;
SELECT * FROM tab13 ORDER BY u1;
U1(int) |R1(int) |R2(int) |G1(int) |G2(int) |G3(int) |
------------------------------------------------------------------------------
1001 |10 |11 |21 |-1 |1 |
------------------------------------------------------------------------------
1002 |20 |21 |41 |-1 |1 |
------------------------------------------------------------------------------
1003 |30 |31 |61 |-1 |1 |
总数目:3
-- 更新数据(生成列的依赖列)
UPDATE tab13 SET r1 = r1 + 10000;
SELECT * FROM tab13 ORDER BY u1;
U1(int) |R1(int) |R2(int) |G1(int) |G2(int) |G3(int) |
------------------------------------------------------------------------------
1001 |10010 |11 |10021 |9999 |-9999 |
------------------------------------------------------------------------------
1002 |10020 |21 |10041 |9999 |-9999 |
------------------------------------------------------------------------------
1003 |10030 |31 |10061 |9999 |-9999 |
总数目:3
-- 更新数据(生成列)
UPDATE tab13 SET g1 = g1 + 10000;
SELECT * FROM tab13 ORDER BY u1;
U1(int) |R1(int) |R2(int) |G1(int) |G2(int) |G3(int) |
------------------------------------------------------------------------------
1001 |10010 |11 |10021 |9999 |-9999 |
------------------------------------------------------------------------------
1002 |10020 |21 |10041 |9999 |-9999 |
------------------------------------------------------------------------------
1003 |10030 |31 |10061 |9999 |-9999 |
总数目:3
-- 删除表
DROP TABLE tab13;
示例14: 创建表(使用 IF NOT EXISTS 选项)
-- 清理环境
DROP TABLE tab14;
-- 创建表tab14(正常被创建)
CREATE TABLE IF NOT EXISTS tab14(a INT);
-- 创建表tab14(不会创建并且不报错)
CREATE TABLE IF NOT EXISTS tab14(a INT);