




CREATE STATISTICS¶
说明¶
基于给出的一列或一组列创建一个统计信息
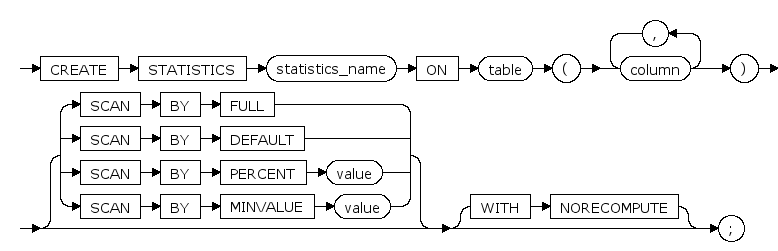
参数¶
staistics_name
要创建的统计的名称。统计名必须符合标识符规则,并且在同一个表上的统计名称必须唯一。
table
在其上计算统计信息的表名。
column
是要在其上创建统计的一列或一组列的名称。
SCAN BY DEFAULT
指定按缺省的方式读取表中的行以收集统计信息。
SCAN BY FULL
指定应读取表中的所有行以收集统计信息。
SCAN BY PERCENT value
按指定比例的方法读取表中的行以收集统计信息。value是指定的比例,必须介于1到100之间。scan by percent 100和scan by full具有相同的行为。
SCAN BY MINVALUE value
按指定的最小数目对表中的行进行采样以计算统计信息。value是采样的最小数目,可以是从0到n的总行数。
NORECOMPUTE
指定应禁用统计的自动重新计算功能。如果指定了该选项,则即使表中的数据进行了更新,统计信息也不会自动更新。
注解
只有在表上才可以建立统计信息,不管表中是否有数据,都是可以新建一个统计的。
但是需要注意的是,create statistics只是建立了这样一个统计并给出了缺省的统计方式,包括采样方式,是否基于索引等等,却并不去进行真正的统计值的计算。统计值的计算需要显示的调用update statistics。这样做的原因是因为有些统计可能是非常耗时的,把建立统计和实际计算统计值的行为分开可以让训练有素的管理员先创建一个统计并将统计的计算和更新在以后进行合理的调度。
创建统计信息可以同时指定表中的几列,系统将会用指定的统计方法对同时指定的列分别计算该列的统计结果。
统计的各种可选方式只能指定其中一种,比如,不能又指定scan by percent同时又指定scan by full。虽然可能scan by percent 100和scan by full具有同样的行为。当然,在建立统计的时候也可以根本不指定其中任何一种方式,这种情况下,系统会按照缺省的方式来建立该统计。
在神通数据库系统中,一个统计是由统计的名称和在其上的表名唯一确定的,这也就是说,用户可以在不同的表上建立相同名称的统计,虽然这样的命名我们是不推荐的。
可通过系统表 SYS_STATISTICS 查看统计信息是否创建成功。
示例¶
示例1: 建立一个基于全扫描方式的统计
-- 清理环境
DROP STATISTICS stat1 ON tab1;
DROP TABLE tab1 CASCADE;
-- 创建表
CREATE TABLE tab1(a INT, b INT);
-- 对 tab1 表中的 a 列建立一个基于全扫描的统计
CREATE STATISTICS stat1 ON tab1(a) SCAN BY FULL;
-- 删除统计和表
DROP STATISTICS stat1 ON tab1;
DROP TABLE tab1;
示例2: 建立一个基于按比例采样方式的统计
如果表中的元组过多,全扫描的方式会产生很大的系统开销,因此,可以指定统计的采样方式为按比例产生采样结果。
-- 清理环境
DROP STATISTICS stat2 ON tab2;
DROP TABLE tab2 CASCADE;
-- 创建表
CREATE TABLE tab2(a INT, b INT);
-- 建立一个基于按比例采样方式的统计
-- 系统将会自动抽取 tab2 表 a 列中 25% 的元组来进行采样
CREATE STATISTICS stat2 ON tab2(a) SCAN BY PERCENT 25;
-- 删除统计和表
DROP STATISTICS stat2 ON tab2;
DROP TABLE tab2;
示例3: 建立一个基于最少值采样方式的统计
系统也支持采样指定元组数的采样方式,在这种情况下,系统将随机抽取指定的元组数来生成统计信息。 当然,如果表中的元素小于指定的最少采样值,系统将以全扫描采样方式来计算和更新统计。
-- 清理环境
DROP STATISTICS stat3 ON tab1;
DROP TABLE tab3 CASCADE;
-- 创建表
CREATE TABLE tab3(a INT, b INT);
-- 建立一个基于最少值采样方式的统计
-- 系统将随机抽取指定的元组数来生成统计信息
CREATE STATISTICS stat3 ON tab3(a) SCAN BY MINVALUE 1000;
-- 删除统计和表
DROP STATISTICS stat3 ON tab3;
DROP TABLE tab3;