




CREATE INDEX¶
说明¶
为给定表创建索引
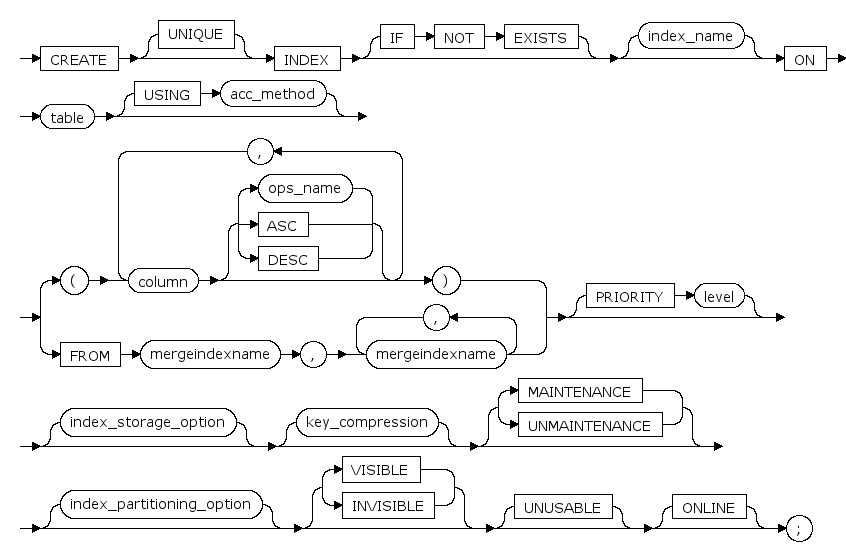





参数¶
UNIQUE
为表创建唯一索引(不允许存在索引值相同的两行)。
在创建索引时,如果数据已存在,数据库会检查是否有重复值,并在每次使用 INSERT 或 UPDATE 语句添加数据时进行这种检查。如果存在重复的键值,将取消 CREATE INDEX 语句,并返回错误信息,
当创建 UNIQUE 索引时,允许有多个NULL值。
IF NOT EXISTS
当不存在同名索引时创建索引 当存在同名索引时提示已存在同名索引
index_name
是索引名。索引名在数据库中的模式中必须唯一。索引名必须遵循标识符规则。
同一模式下,表、索引、视图、序列不能同名。
索引名可以缺省,如果缺省时,会自动创建唯一的索引名。命名规则如下:
- 如果创建的是唯一性索引时,索引名为:表名 _ 列名1 _ 列名2 _ ... _ 列名n _ KEY
- 如果创建表达式索引时,索引名为:表名 _ EXPR _ IDX
- 普通索引名为:表名 _ 列名1 _ 列名2 _ ... _ 列名n _IDX
注解
每张表只能建一个缺省索引名的表达式索引。
table
包含要创建索引的列的表。
USING acc_method
用于索引的访问模式.目前数据库支持BTREE,BITMAP.
column
应用索引的列。
ops_name
为索引的每个列声明的操作符表,操作符表标识将要被该索引用于该列/字段的操作符,实际上,该域的数据类型的缺省操作符表一般就足够了.某些数据类型有操作符表的原因是,它们可能有多于一个的有意义的顺序。
n
是表示前面的项可重复 n 次的占位符
mergeindexname
要在该表上合并的索引的名字
PRIORITY level
为该索引指定一个优先级参数,该参数表明了在生成执行计划时,该索引被考虑使用的优先级别,数值越大,表示其优先级越低,优先级为0的索引的优先级最高.当用户创建或修改索引时如果不指定其优先级,优化器就按常规的代价估算来进行路径选择,选择代价最小的索引来生成执行计划。用户一般不需要为索引指定优先级,
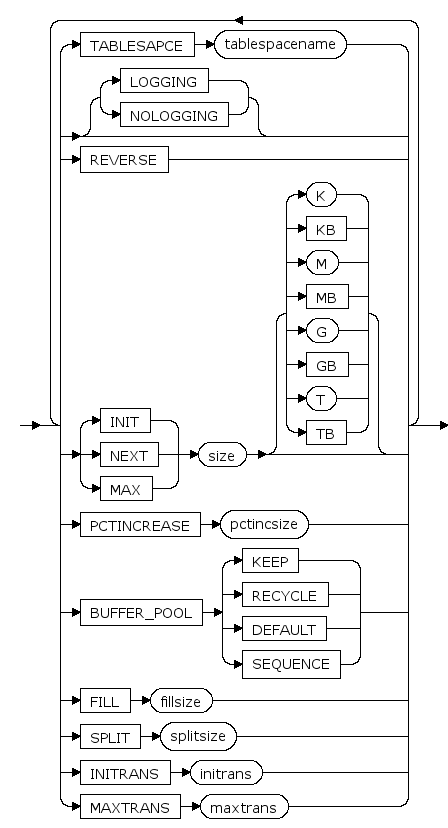
TABLESPACE tablespacename
索引所属的表空间名
LOGGING | NOLOGGING
对索引进行的操作记日志或不记日志。
- NOLOGGING可以使对象上的操作产生的日志量最少,通常指定NOLOGGING可以改善大数据量操作的性能,对少量数据的操作只有很小的影响,在大数据量NOLOGGING操作结束后应当将对象改回LOGGING模式。除以下操作外,不建议对其它操作使用NOLOGGING模式:
- CREATE INDEX
- ALTER INDEX REBUILD
- INSERT INTO ... SELECT
- 大量的大对象数据操作
由于NOLOGGING模式下记录的少量日志无法满足数据库回滚和介质恢复的需要,你必须非常谨慎地使用这种模式,而且要与负责备份和恢复的人沟通之后才能使用。在执行NOLOGGING操作前应当为可能受影响的数据文件建立一个备份,一旦操作失败或发生事务回滚,必须从备份进行恢复,以避免产生数据不一致的情况。 执行NOLOGGING操作后,必须执行ALTER SYSTEM CHECKPOINT命令建立检查点强制数据刷新到磁盘上,并尽快为受影响的数据文件建立一个新的基准备份,从而避免由于介质失败而丢失对这些对象的后续修改。
对象之间的LOGGING属性是相互独立的,表与LOB字段、表与索引的LOGGING属性都不会互相影响。例如,如果想对索引在NOLOGGING模式下重建,只需执行ALTER INDEX ... REBUILD NOLOGGING. 并不需要对表进行NOLOGGING设置。
REVERSE
只有在访问方法为BTREE时可以使用此选项,标明此选项后BTREE将为倒序BTREE索引。
INIT size [ K | KB | M | MB | G | GB | T | TB ]
索引大小的初始值, K,KB,M,MB,G,GB,T,TB分别是可选的字节单位
默认是M(兆字节)
NEXT size [ K | KB | M | MB | G | GB | T | TB ]
索引大小的增长步长, K,KB,M,MB,G,GB,T,TB分别是可选的字节单位,增长步长为64k的倍数
默认是M(兆字节)
PCTINCREASE pctincsize
段增长步长的增长比例。每次段增长的大小比上次段增长的大小多pctincsize%
MAX size [ K | KB | M | MB | G | GB | T | TB ]
索引大小的最大值,K,KB,M,MB,G,GB,T,TB分别是可选的字节单位
默认是M(兆字节)
BUFFER_POOL {KEEP|RECYCLE|DEFAULT|SEQUENCE}
BUFFER_POOL子句用于为指定的模式对象指定一个默认的缓存方式。
- 指定KEEP,表示尽量将该模式对象数据缓存在内存中;
- 指定RECYCLE,表示采用LRU算法换出该模式对象数据;
- 指定SEQUENCE,表示按顺序换出该模式对象数据;
指定DEFAULT时,表示采用系统默认的缓存方式,当前系统默认缓存方式为 RECYCLE。
FILL fillsize
索引填充系数,详见 sys_segment(段信息) 的 PCTFREE 列的说明
SPLIT splitsize
索引分裂系数,详见 sys_segment(段信息) 的 PCTUSED 列的说明
INITRANS initrans
页面上的初始事务槽数。 当事务对页面进行首次更新操作时,需要先占用一个本页面里的事务槽。在此事务结束后,占用的事务槽才可被其它事务重新占用。 initrans取值范围是[1, maxtrans]。
不指定的话默认值是2
MAXTRANS maxtrans
页面上的事务槽扩展上限。 当页面的initrans事务槽不够用时,如果页面有空闲空间,可以自动进行事务槽的扩展,扩展到不超过maxtrans个事务槽。 maxtrans取值范围是[1, 255]。
不指定的话默认值是255
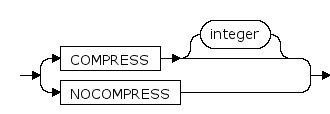
COMPRESS [integer] | NOCOMPRESS
通过指定COMPRESS关键字消除重复键列值,可以大幅降低磁盘存储空间。
- 指定COMPRESS,表示对表数据压缩存储。COMPRESS后跟integer以指定压缩列前的列数。
- 指定NOCOMPRESS,表示表数据不压缩存储。
默认是NOCOMPRESS。
MAINTENANCE | UNMAINTENANCE
索引处于维护状态或非维护状态
默认为非维护状态,即正常状态。
VISIBLE | INVISIBLE
索引可见或不可见状态。不可见索引依然会随数据表的改变而更新,但是不会被数据库内部使用。
默认为可见状态。
ASC | DESC
确定具体某个索引列的升序或降序排序方向。
默认设置为 ASC。
LOCAL | GLOBAL
索引是局部索引还是全局索引。
PARTITION partition
索引分区的名字。
PARTITION BY RANGE / HASH
建立范围或哈希索引分区。
PARTITION…literal
一个合法的分区键值。
PARTITION…expr_list
建立索引分区时,分区键依赖的列。expr_list最多可以包含32列。expr_list必须是索引列的左前缀结合,例如索引健为(a,b,c),那么全局索引分区健则可以是(a,b,c), (a,b), (a,c),而不可以是(b,c),(c),(b,a)。
PARTITION hash_partition_quantity
哈希索引分区的分区数目。
PARTITION…table_partition_description
此处只能哈希分区索引定义tablespace,不能为lob列定义存储参数。
UNUSABLE
设置索引的状态为UNUSABLE
不能将临时表上的索引设置为UNUSABLE
ONLINE
指定使用在线方式创建索引。
使用在线方式在创建过程中可以减少对其他事务 DML 操作表的阻塞。
注解
索引主要用来提高数据库性能.但是如果不恰当的使用将导致性能的下降.
CREATE INDEX 语句同其它查询一样优化。查询处理器可以选择扫描另一个索引,而不是执行表扫描,以节省 I/O 操作。
局部分区索引是为分区表中的各个分区单独地建立分区,各个索引分区之间是相互独立的。全局分区索引是对整个分区表建立的索引,然后根据分区信息对索引进行分区,全局分区索引支持hash和range两种方式。
如果要在临时表上创建索引,需要注意以下事项:
- 每一个会话第一次向临时表中插入数据时会创建一个与会话相关联的数据段,即临时表的实例化(通过视图v_sys_temp_instance可以查看当前所有的临时表实例),临时表会与该会话绑定,当事务或会话结束时临时表与该事务或会话的绑定将会解除。
- 临时表没有与任何事务或会话绑定时才可以在临时表上创建索引。
- 类似于创建临时表,创建临时表索引时仅保存元数据,不创建索引段,索引段在索引实例化时创建。
- 创建全局临时表索引时支持指定存储参数,但不支持指定初始大小、表空间和nologging模式;创建本地临时表没有限制。
可以通过以下操作提高创建索引的性能:
- 增大SORT_MEM配置参数:如果排序内存可以放下所有需要排序的数据,系统将使用比外排序快得多的内存排序。即使内存中放不下所有的数据,增大排序内存也可以减少内外存交换的次数。
- 增大BUF_DATA_BUFFER_PAGES配置参数:增大数据缓冲区可以减少等待数据回刷的时间。
- 将临时表空间放在与普通数据表空间不同的磁盘上:外排序将会读写临时表空间,通过将临时表空间放在不同的磁盘上可以避免同时对一块磁盘进行读写操作。
4. 使用nologging选项:使用nologging选项可以减少大量的事务日志记录,因而可以减少大量的磁盘IO。注意:创建完索引后应当马上进行检查点操作,并使用alter index logging修改索引。
示例¶
示例1: 创建简单索引
-- 清理环境
DROP INDEX idx1 CASCADE;
DROP TABLE tab1 CASCADE;
-- 创建表
CREATE TABLE tab1 (a INT, b INT);
-- 创建简单索引
CREATE INDEX idx1 ON tab1(b);
--创建简单索引
CREATE INDEX IF NOT EXISTS idx2 ON tab1(a);
-- 删除索引和表
DROP INDEX idx1;
DROP INDEX idx2;
DROP TABLE tab1;
示例2: 创建简单组合索引
-- 清理环境
DROP INDEX idx2 CASCADE;
DROP TABLE tab2 CASCADE;
-- 创建表
CREATE TABLE tab2 (a INT, b INT, c INT, d INT);
-- 创建简单组合索引
CREATE INDEX idx2 ON tab2(c, a);
-- 删除索引和表
DROP INDEX idx2;
DROP TABLE tab2;
示例3: 创建合并索引
-- 清理环境
DROP INDEX idx5 CASCADE;
DROP INDEX idx4 CASCADE;
DROP INDEX idx3 CASCADE;
DROP TABLE tab3 CASCADE;
-- 创建表
CREATE TABLE tab3 (a INT, b INT, c INT, d INT);
-- 创建简单组合索引
CREATE INDEX idx3 ON tab3(a, b);
CREATE INDEX idx4 ON tab3(b, c);
-- 创建合并索引
CREATE INDEX idx5 ON tab3 FROM idx3, idx4;
-- idx3 、 idx4 已不存在
DROP INDEX idx3;
ERROR, 索引 "IDX3" 不存在或无权访问
DROP INDEX idx4;
ERROR, 索引 "IDX4" 不存在或无权访问
DROP INDEX idx5;
-- 删除表
DROP TABLE tab3;
示例4: 创建索引(指定物理存储参数)
-- 清理环境
DROP INDEX idx4 CASCADE;
DROP TABLE tab4 CASCADE;
-- 创建表
CREATE TABLE tab4 (a INT, b INT);
-- 创建简单索引(指定物理存储参数)
CREATE INDEX idx4 ON tab4(a) INIT 2M NEXT 4M FILL 70 SPLIT 50;
-- 删除索引和表
DROP INDEX idx4;
DROP TABLE tab4;
示例5: 创建索引(带有索引约束)
-- 清理环境
DROP INDEX idx5 CASCADE;
DROP TABLE tab5 CASCADE;
-- 创建表
CREATE TABLE tab5 (a INT, b INT);
-- 创建简单索引(带有索引约束)
CREATE INDEX idx5 ON tab5(a) UNUSABLE;
-- 删除索引和表
DROP INDEX idx5;
DROP TABLE tab5;
示例6: 创建简单索引(指定索引缓存方式、压缩级别)
-- 清理环境
DROP INDEX idx6 CASCADE;
DROP TABLE tab6 CASCADE;
-- 创建表
CREATE TABLE tab6 (a INT, b INT);
-- 创建简单索引(指定索引缓存方式、压缩级别)
CREATE INDEX idx6 ON tab6(a) BUFFER_POOL KEEP COMPRESS 1;
-- 删除索引和表
DROP INDEX idx6;
DROP TABLE tab6;
示例7: 创建局部分区索引
-- 清理环境
DROP INDEX idx7 CASCADE;
DROP TABLE tab7 CASCADE;
-- 创建分区表
CREATE TABLE tab7 (a INT, b INT)
PARTITION BY RANGE(a)
(
PARTITION p1 VALUES LESS THAN (100),
PARTITION p2 VALUES LESS THAN (200),
PARTITION p3 VALUES LESS THAN (300),
PARTITION p4 VALUES LESS THAN (MAXVALUE)
);
-- 创建局部分区索引
CREATE INDEX idx7 ON tab7(a) LOCAL;
-- 删除索引和表
DROP INDEX idx7;
DROP TABLE tab7;
示例8: 创建全局分区索引
-- 清理环境
DROP INDEX idx10 CASCADE;
DROP INDEX idx9 CASCADE;
DROP INDEX idx8 CASCADE;
DROP TABLE tab8 CASCADE;
-- 创建表
CREATE TABLE tab8 (a INT, b INT)
PARTITION BY RANGE(a)
(
PARTITION p1 VALUES LESS THAN (100),
PARTITION p2 VALUES LESS THAN (200),
PARTITION p3 VALUES LESS THAN (300),
PARTITION p4 VALUES LESS THAN (MAXVALUE)
);
-- 创建全局 hash 分区索引
CREATE INDEX idx8 ON tab8(b) GLOBAL PARTITION BY HASH(b) PARTITIONS 8;
-- 删除索引
DROP INDEX idx8;
-- 创建全局 hash 分区索引
CREATE INDEX idx9 ON tab8(b) GLOBAL PARTITION BY HASH(b)
(
PARTITION p1,
PARTITION p2,
PARTITION p3,
PARTITION p4
);
-- 删除索引
DROP INDEX idx9;
-- 创建全局 range 分区索引
CREATE INDEX idx10 ON tab8(b)
GLOBAL PARTITION BY RANGE(b)
(
PARTITION i10_p1 VALUES LESS THAN (1000),
PARTITION i10_p2 VALUES LESS THAN (maxvalue)
);
-- 删除索引
DROP INDEX idx10;
-- 删除表
DROP TABLE tab8;
示例9: 创建局部分区索引
-- 清理环境
DROP INDEX idx11 CASCADE;
DROP INDEX idx10 CASCADE;
DROP INDEX idx9 CASCADE;
DROP TABLE tab9 CASCADE;
-- 创建表
CREATE TABLE tab9 (a INT, b INT, c INT)
PARTITION BY HASH(a, b) PARTITIONS 4;
-- 创建前缀局部分区索引
CREATE INDEX idx9 ON tab9(a, b) LOCAL;
-- 删除索引
DROP INDEX idx9;
-- 创建前缀局部分区索引
CREATE INDEX idx10 ON tab9(b, a) LOCAL;
-- 删除索引
DROP INDEX idx10;
-- 索引项完全独立于分区键
CREATE INDEX idx11 ON tab9(c) LOCAL;
-- 删除索引
DROP INDEX idx11;
-- 删除表
DROP TABLE tab9;
示例10: 创建唯一局部分区索引
-- 清理环境
DROP INDEX idx10 CASCADE;
DROP TABLE tab10 CASCADE;
-- 创建表
CREATE TABLE tab10(a INT, b INT, c INT)
PARTITION BY HASH(a, b) PARTITIONS 4;
-- 创建唯一局部分区索引, 索引项未包含分区键, 创建失败
CREATE UNIQUE INDEX idx10 ON tab10(a) LOCAL;
ERROR, 分区列必须构成UNIQUE索引的关键字列子集
-- 创建唯一局部分区索引, 索引项包含分区键, 创建成功
CREATE UNIQUE INDEX idx10 ON tab10(b, a) LOCAL;
-- 删除索引
DROP INDEX idx10;
-- 删除表
DROP TABLE tab10;
示例11: 在线创建索引
-- 清理环境
DROP INDEX idx11 CASCADE;
DROP TABLE tab11 CASCADE;
-- 创建表
CREATE TABLE tab11(a INT, b INT, c INT);
-- 在线创建索引
CREATE UNIQUE INDEX idx11 ON tab11(a) ONLINE;
-- 删除索引
DROP INDEX idx11;
-- 删除表
DROP TABLE tab11;
示例12: 创建缺省索引名的索引
-- 清理环境
-- 清理环境
DROP TABLE tab12 CASCADE;
-- 创建表
CREATE TABLE tab12(a INT, b INT, "a" INT);
-- 创建普通索引, 索引名缺省
CREATE INDEX ON tab12(a);
CREATE INDEX ON tab12(b);
CREATE INDEX ON tab12("a");
SELECT * FROM V_SYS_INDEXES WHERE tablename='TAB12' ORDER BY INDEXNAME;
SCHEMANAME(name) |TABLENAME(name) |INDEXSCHEMANAME(name) |INDEXNAME(name) |FILLCOEF(smallint) |INDEXDEF(text) |ISPRIMARY(boolean) |ISUNIQUE(boolean) |
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SYSDBA |TAB12 |SYSDBA |TAB12_A_IDX |70 |CREATE INDEX TAB12_A|false |false |
| | | | |_IDX ON SYSDBA.TAB1| | |
| | | | |2 USING BTREE (A) P| | |
| | | | |RIORITY 0 VISIBLE | | |
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SYSDBA |TAB12 |SYSDBA |TAB12_B_IDX |70 |CREATE INDEX TAB12_B|false |false |
| | | | |_IDX ON SYSDBA.TAB1| | |
| | | | |2 USING BTREE (B) P| | |
| | | | |RIORITY 0 VISIBLE | | |
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
SYSDBA |TAB12 |SYSDBA |TAB12_a_IDX |70 |CREATE INDEX "TAB12_|false |false |
| | | | |a_IDX" ON SYSDBA.TA| | |
| | | | |B12 USING BTREE ("a| | |
| | | | |") PRIORITY 0 VISIB| | |
| | | | |LE | | |
总数目:3
-- 删除索引
DROP INDEX tab12_a_idx;
DROP INDEX tab12_b_idx;
DROP INDEX "TAB12_a_IDX";
-- 删除表
DROP TABLE tab12;