




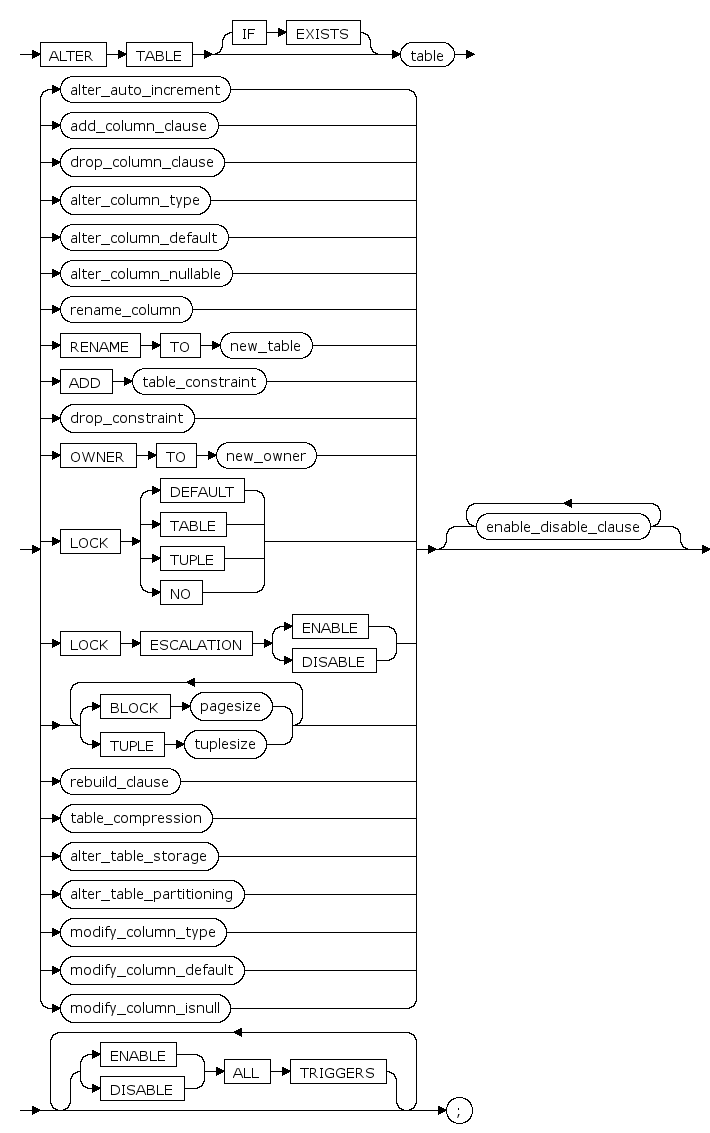
ALTER TABLE¶
说明¶
通过更改、添加、除去列和约束来更改表的定义。
语法¶
alter_table ::=


use_index_clause ::=


defer_option ::=
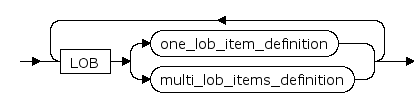
multi_lob_items_definition ::=


lob_parameters ::=


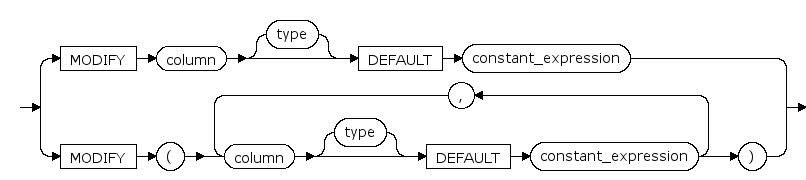


rename_column ::=

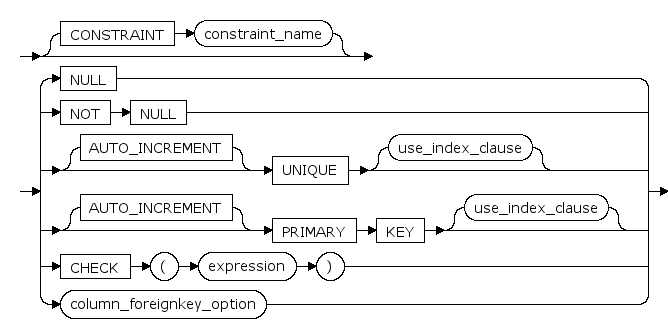
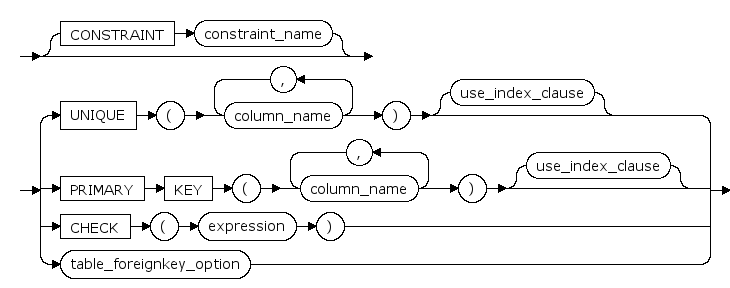
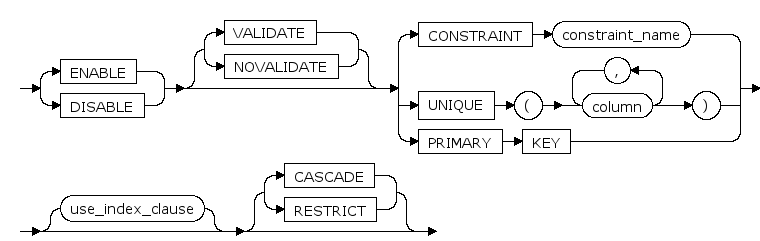
table_constraint ::=
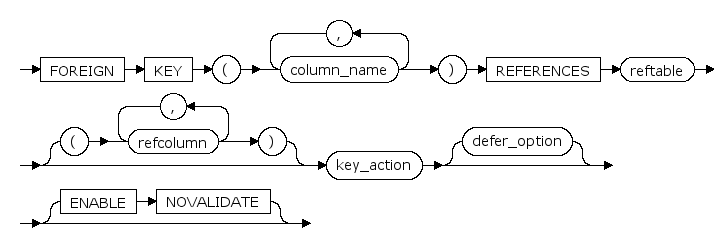
key_action ::=
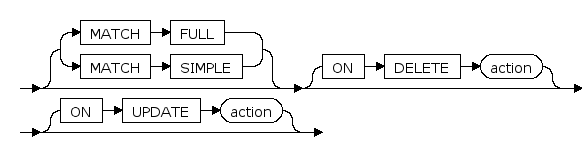
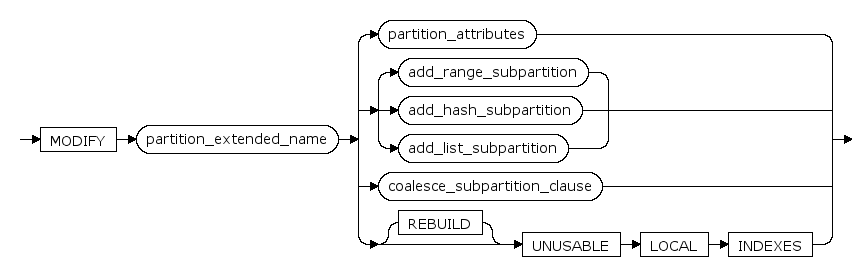
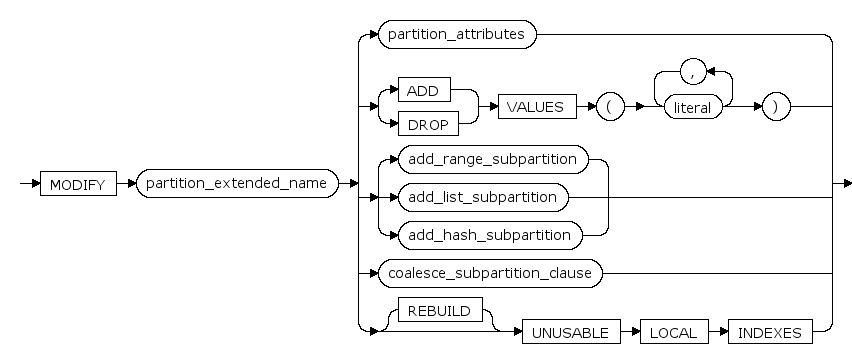
action ::=
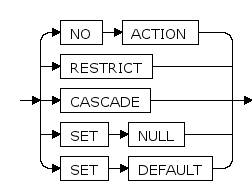
drop_constraint ::=

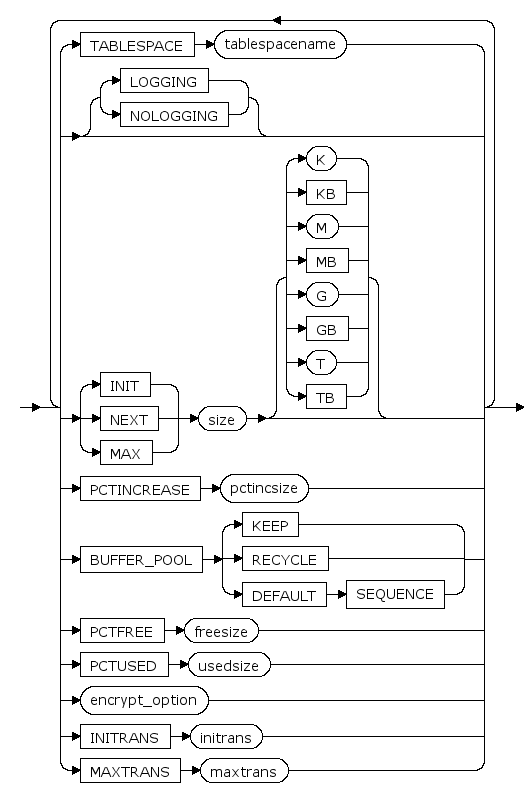
rebuild_clause ::=
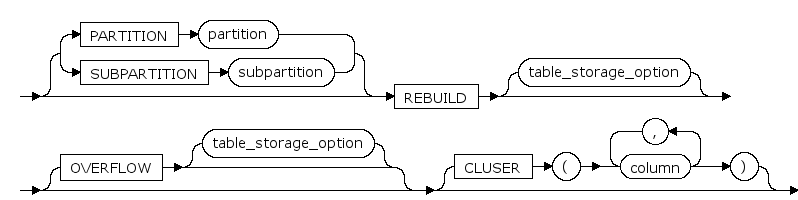
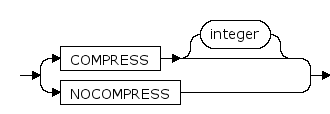
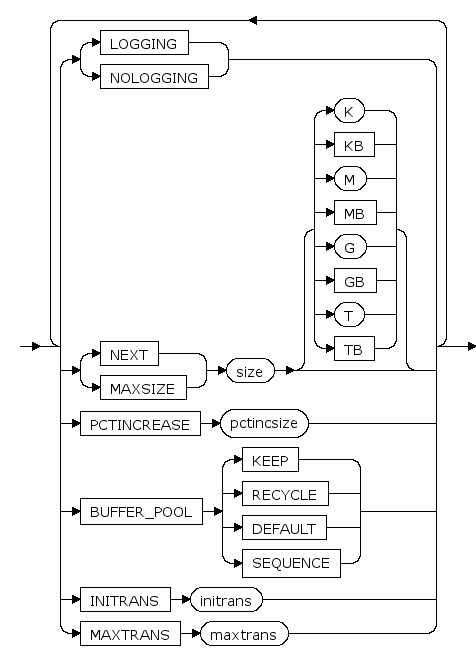
modify_table_default_attrs ::=


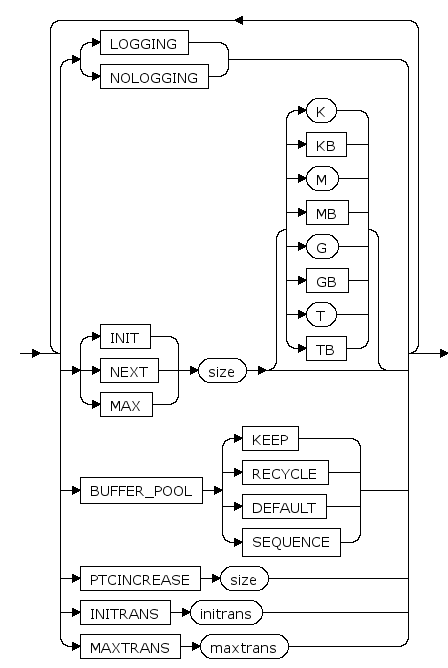
alter_partition_table_storage ::=
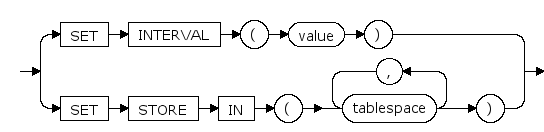
alter_interval_partitioning ::=
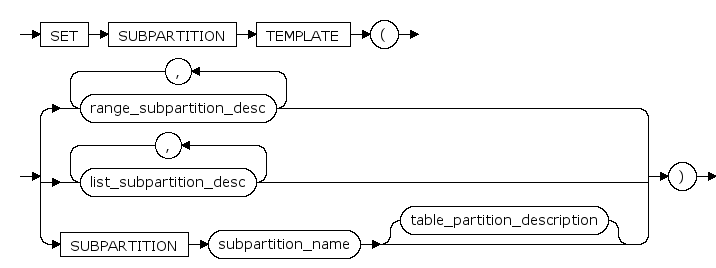


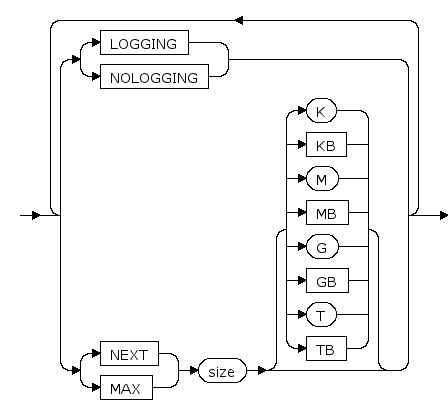



coalesce_subpartition_clause ::=

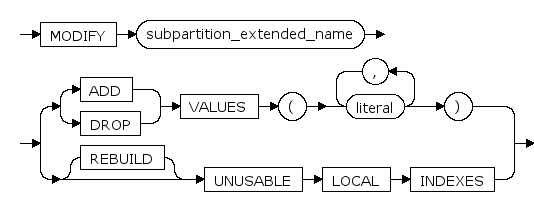





add_range_partition_clause ::=
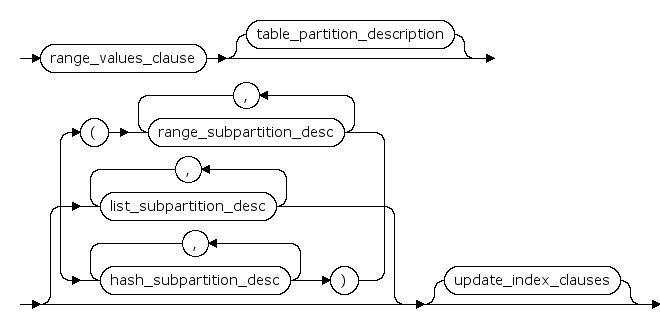
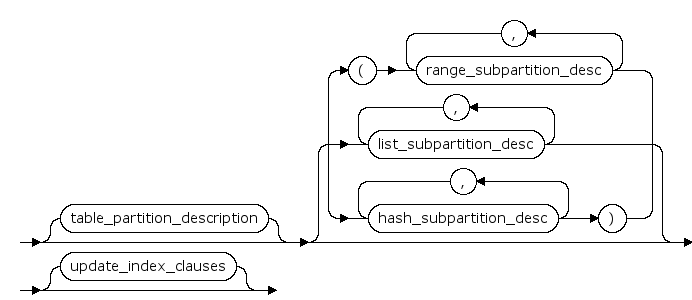
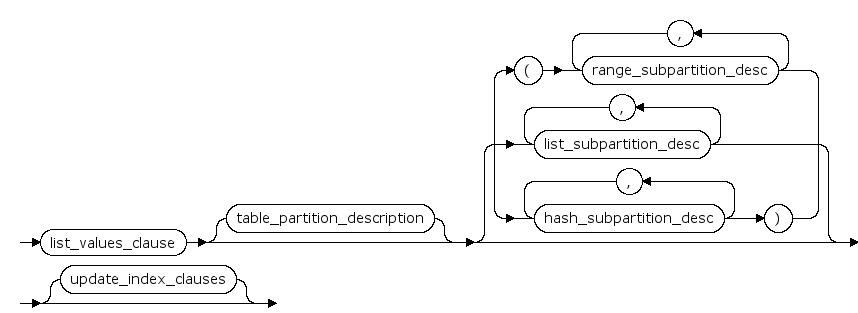
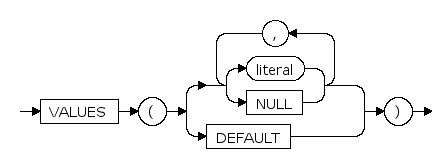
table_partition_description ::=


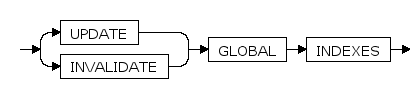
update_global_index_clause ::=


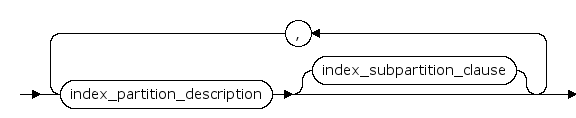
index_partition_description ::=


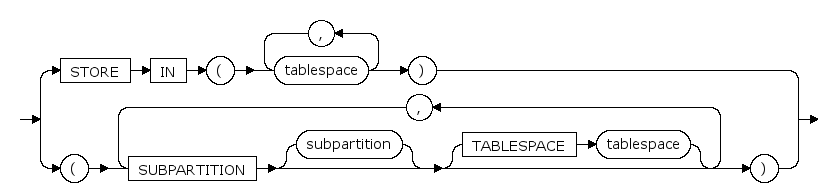
coalesce_table_subpartition ::=



subpartition_extended_name ::=
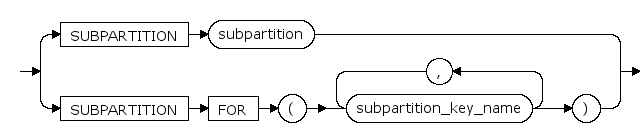

truncate_partition_subpart ::=


partition_spec ::=


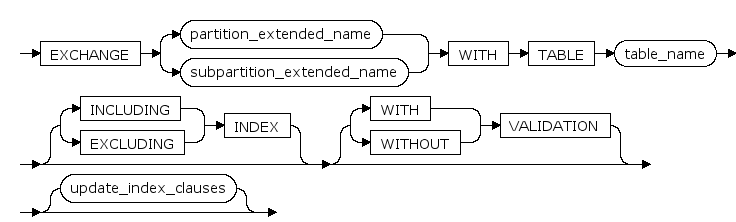
exchange_partition_subpart ::=
encrypt_option ::=
参数¶
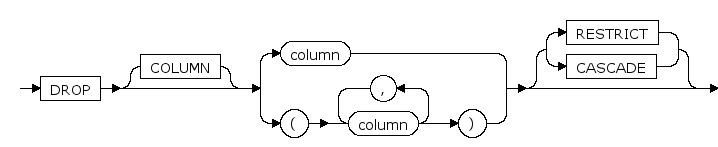
add_column_clause
指定要添加一个或多个列定义
IF EXISTS
当存在一个同名的关系时会修改表,否则不会修改表,且会打印NOTICE提示信息
table
是要更改的表的名称。如果表不在当前数据库中或者不属于当前用户所拥有,可以显式指定数据库和模式名
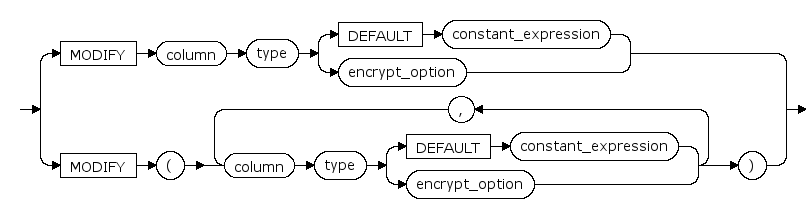
column
是要更改、添加或除去的列的名称。
type
新字段的类型或现存字段的新类型。
ALTER COLUMN TYPE
改变表中一个字段的类型。该字段涉及的索引和简单的表约束被自动地转换为使用新的字段类型。
AUTO_INCREMENT
声明该列为自增列。
ADD列时,可以添加自增列,但添加后表中至多只有一列自增列,且自增列的数据类型为整型或浮点类型,有单独的PRIMARY KEY或UNIQUE约束,否则报错。
ALTER COLUMN TYPE修改列类型时,可以使用AUTO_INCREMENT关键字。如果修改之前该列为自增列,需要使用AUTO_INCREMENT关键字声明该列为自增列,否则,列将由自增列变为普通列。如果修改前该列为普通列,不能使用此关键字,否则将报错。
MODIFY为兼容Oracle的用法,不能使用AUTO_INCREMENT关键字。
不能删除自增列独有的约束,自增列的组合约束可以删除。
DEFAULT default_expr
DEFAULT
子句给它所出现的字段一个缺省数值.该数值可以是任何不含变量的表达式(不允许使用子查询和对本表中的其它字段的交叉引用).缺省表达式的数据类型必须和字段类型匹配.
n
是表示前面的项可重复 n 次的占位符。
RESTRICT | CASCADE
- RESTRICT
对应action 的选项时。确保只有不存在完整性约束的表才可以被删除。
禁用约束时,仅当没有其它约束依赖于该约束时,才会禁用约束。
- CASCADE
对应action 的选项时,任何引用的视图或完整性约束都将被删除。
禁用约束时,强制禁用约束,并强制禁用依赖于该约束的其它约束。
默认为RESTRICT
ALTER [ COLUMN ]
指定要更改给定列。
SET DEFAULT constant_expression
设置列的默认值属性, DEFAULT 子句给它所出现的字段一个缺省数值.该数值可以是任何不含变量的表达式(不允许使用子查询和对本表中的其它字段的交叉引用).缺省表达式的数据类型必须和字段类型匹配。
DROP DEFAULT
删除列的默认值属性。
{ SET | DROP } NOT NULL
设置或者删除列的非空属性。
RENAME [ COLUMN ] column TO
改变表中一个独立字段的名字.它对存储的数据没有任何影响。
new_column
现存列的新名称。
RENAME TO
改变一个表的名字(或者是一个索引,一个序列,或者一个视图),对存储的数据没有任何影响。
new_table
表的新名称。
ADD table_constraint_definition
这个形式给表增加一个新的约束。
DROP CONSTRAINT constraint_name
指定从表中删除constraint_name,注意:修改NULL,NOTNULL约束请使用ALTER TABLE ALTER [ COLUMN ] column { SET | DROP } NOT NULL子句。
DROP PRIMARY KEY
指定从表中删除主键PRIMARY KEY。
OWNER TO
这个形式改变表,索引,序列或者视图的所有者为指定所有者。
new_owner
该表的新所有者的用户名。
LOCK { DEFAULT | TABLE | TUPLE | NO}
建议执行过程加锁模式。
DEFAULT建议由执行过程自动决定。
TABLE建议执行过程对表级锁, 不加行锁。
TUPLE建议执行过程对表加意向锁,对具体操作的元组加行级锁。
NO建议执行过程对表不加锁。
一般情况下应该使用LOCK DEFAULT选项, LOCK TABLE可以减少加锁数量,降低加锁开销,但可能降低并发度.LOCK TUPLE有利于提高并发度,但会增加加锁数量,增加加锁开销。
LOCK ESCALATION{ENABLE | DISABLE}
对指定表是否进行锁升级进行控制。当前神通数据库已不再支持该功能,但保留相关语法的使用以保证兼容性。
VISIBLE | INVISIBLE
- VISIBLE索引可见状态
- INVISIBLE索引不可见状态,不可见索引依然会随数据表的改变而更新,但是不会被数据库内部使用。
默认为VISIBLE
BLOCK pagesize
估计一个表占用的页数目。
TUPLE tuplesize
估计一个表的元组数目。
REBUILD [table_storage_option ]
设置表的新的存储参数,整理表的数据到一个连续的块中。
OVERFLOW [table_storage_option]
允许将溢出数据段按索引组织添加到指定的表中。
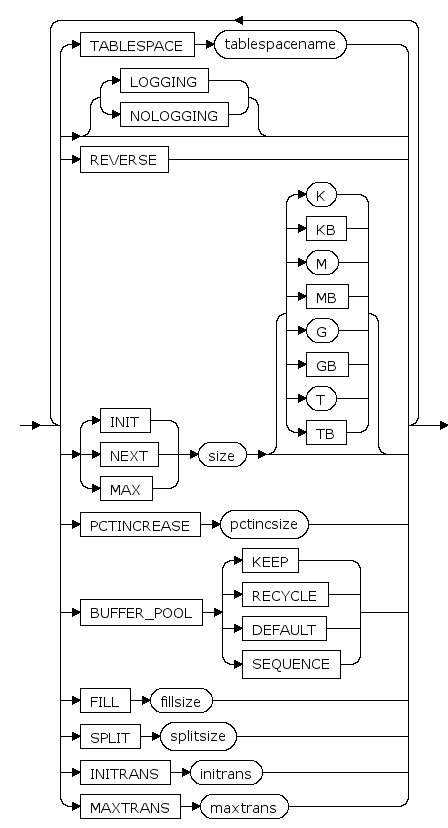
LOGGING | NOLOGGING
设置对索引进行的操作记日志或不记日志。
NOLOGGING可以使对象上的操作产生的日志量最少,通常指定NOLOGGING可以改善大数据量操作的性能,对少量数据的操作只有很小的影响,在大数据量NOLOGGING操作结束后应当将对象改回LOGGING模式。除以下操作外,不建议对其它操作使用NOLOGGING模式:
CREATE INDEX
ALTER INDEX REBUILD
INSERT INTO ... SELECT
大量的大对象数据操作
由于NOLOGGING模式下记录的少量日志无法满足数据库回滚和介质恢复的需要,你必须非常谨慎地使用这种模式,而且要与负责备份和恢复的人沟通之后才能使用。在执行NOLOGGING操作前应当为可能受影响的数据文件建立一个备份,一旦操作失败或发生事务回滚,必须从备份进行恢复,以避免产生数据不一致的情况。 执行NOLOGGING操作后,必须执行ALTER SYSTEM CHECKPOINT命令建立检查点强制数据刷新到磁盘上,并尽快为受影响的数据文件建立一个新的基准备份,从而避免由于介质失败而丢失对这些对象的后续修改。
对象之间的LOGGING属性是相互独立的,表与LOB字段、表与索引的LOGGING属性都不会互相影响。例如,如果想对索引在NOLOGGING模式下重建,只需执行ALTER INDEX ... REBUILD NOLOGGING. 并不需要对表进行NOLOGGING设置。
REVERSE
只有在访问方法为BTREE时可以使用此选项,标明此选项后BTREE将为倒序BTREE索引。
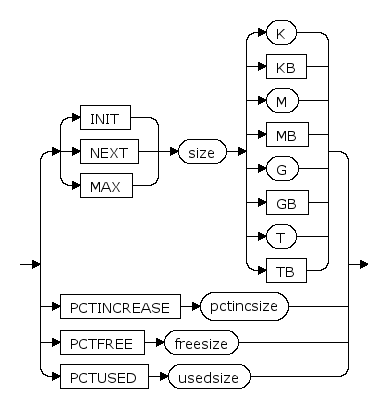
NEXT size [ K | KB | M | MB | G | GB | T | TB ]
设置主分区大小的增长步长, K,KB,M,MB,G,GB,T,TB分别是可选的字节单位,增长步长为64k的倍数。
默认是M(兆字节)
PCTINCREASE pctincsize
段增长步长的增长比例。每次段增长的大小比上次段增长的大小多pctincsize%
MAX size [ K | KB | M | MB | G | GB | T | TB ]
设置主分区大小的最大值,K,KB,M,MB,G,GB,T,TB分别是可选的字节单位。
默认是M(兆字节)
BUFFER_POOL {KEEP|RECYCLE|DEFAULT|SEQUENCE}
BUFFER_POOL子句用于为指定的模式对象指定一个默认的缓存方式。
- 指定KEEP,表示尽量将该模式对象数据缓存在内存中;
- 指定RECYCLE,表示采用LRU算法换出该模式对象数据;
- 指定SEQUENCE,表示按顺序换出该模式对象数据;
指定DEFAULT时,表示采用系统默认的缓存方式,当前系统默认缓存方式为RECYCLE。
COMPRESS [integer] | NOCOMPRESS
- 指定COMPRESS,表示对表数据压缩存储。COMPRESS后跟integer以指定压缩等级;
- 指定NOCOMPRESS,表示表数据不压缩存储。
默认是NOCOMPRESS。
NULL | NOT NULL
是确定列中是否允许空值的关键字。不允许空值的列只有在指定了默认值的情况下, 才能用 ALTER TABLE 语句向表中添加。添加到表中的新列要么允许空值,要么必须指定默认值。
如果新列允许空值,而且没有指定默认值,那么新列在表中每一行都包含空值。如果新列允许空值并且指定了新列的默认值,那么每一行都包含默认值
如果新列不允许空值,那么新列必须具有 DEFAULT 定义,而且新列的所有现有行中将自动装载该默认值。
可在 ALTER COLUMN 语句中DROP NOT NULL 以使 NOT NULL 列允许空值,但 PRIMARY KEY 约束中的列除外。只有列中不包含空值时,ALTER COLUMN 中才可指定 NOT NULL。必须将空值更新为非空值后,才允许执行 ALTER COLUMN SET NOT NULL 语句。
UNIQUE
是通过唯一索引为给定的一列或多列提供实体完整性的约束。一个表可以有多个 UNIQUE 约束。
PRIMARY KEY
是通过唯一索引对给定的一列或多列强制实体完整性的约束。对于每个表只能创建一个 PRIMARY KEY 约束。
USING INDEX index_name
建表时, 当表具有UNIQUE或PRIMAY KEY约束时, 可以指定创建的唯一性索引的名字。
CHECK (expression)
是通过限制可输入到一列或多列中的可能值强制域完整性的约束。
REFERENCES | FOREIGN KEY ... REFERENCES
是为列中的数据提供引用完整性的约束。FOREIGN KEY 约束要求列中的每个值在被引用表中对应的被引用列中都存在。FOREIGN KEY 约束只能引用被引用表中为PRIMARY KEY 或 UNIQUE 约束的列或被引用表中在 UNIQUE INDEX 内引用的列。
reftable
是 FOREIGN KEY 约束所引用的表名。
( refcolumn ) | ( refcolumn [, ... ] )
是 FOREIGN KEY 约束所引用的表中的一列或多列。
MATCH FULL
向这些列增加的数值将使用给出的匹配类型与参考表的参考列中的数值进行匹配,不允许一个多字段外键的字段为NULL。
ON DELETE
指定当要创建的表中的行具有引用关系,并且从父表中删除该行所引用的行时,要对该行采取的操作。
ON UPDATE
指定当要创建的表中的行具有引用关系,并且在父表中更新该行所引用的行时,要对该行采取的操作。
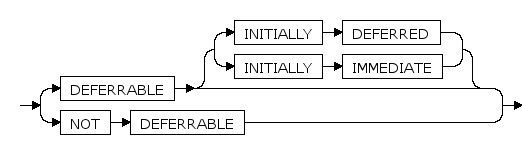
DEFERRABLE | NOT DEFERRABLE
这两个关键字设置该约束是否可推迟。一个不可推迟的约束将在每条命令之后马上检查。可以推迟的约束检查可以推迟到事务结尾。 目前只有外键约束接受这个子句。所有其它约束类型都是不可推迟的。
缺省是 NOT DEFERRABLE。
INITIALLY IMMEDIATE | INITIALLY DEFERRED
如果约束是可推迟的,那么这个子句声明检查约束的缺省时间。如果约束是 INITIALLY IMMEDIATE,那么每条语句之后就检查它。这个是缺省。如果约束是 INITIALLY DEFERRED,那么只有在事务结尾才检查它。
action
- NO ACTION表示删除或者更新将产生一个违反外键约束的动作,生成错误,它是缺省动作。
- RESTRICT对应atction 的一个选项,与NO ACTION 相同。
- CASCADE对应action 的一个选项,删除任何引用了被删除行的行,或者分别把引用行的字段值更新为被参考字段的新数值。
- SET NULL把引用行数值设置为 NULL。
- SET DEFAULT把引用列的数值设置为它们的缺省值。
默认为NO ACTION
TABLESPACE tablespacename
分区所属的表空间名。
INIT size [ K | KB | M | MB | G | GB | T | TB ]
主分区大小的初始值, K,KB,M,MB,G,GB,T,TB分别是可选的字节单位。
默认是M(兆字节)
PCTFREE freesize
保留空闲空间百分比,详见 sys_segment(段信息) 的 PCTFREE 列的说明
PCTUSED usedsize
恢复可插入的空间百分比,详见 sys_segment(段信息) 的 PCTUSED 列的说明
FILL fillsize
索引填充系数,详见 sys_segment(段信息) 的 PCTFREE 列的说明
SPLIT splitsize
索引分裂系数,详见 sys_segment(段信息) 的 PCTUSED 列的说明
INITRANS initrans
页面上的初始事务槽数。 当事务对页面进行首次更新操作时,需要先占用一个本页面里的事务槽。在此事务结束后,占用的事务槽才可被其它事务重新占用。 initrans取值范围是[1, maxtrans]。
不指定的话默认值是2
MAXTRANS maxtrans
页面上的事务槽扩展上限。 当页面的initrans事务槽不够用时,如果页面有空闲空间,可以自动进行事务槽的扩展,扩展到不超过maxtrans个事务槽。 maxtrans取值范围是[1, 255]。
不指定的话默认值是255
lob_item
LOB列名。
lob_segname
LOB列所在的段名,若不指定,则由系统自动生成;每个LOB列必须对应唯一的一个段。
lob_parameters
LOB段的存储参数,若不指定,则使用与主表相同的存储参数。
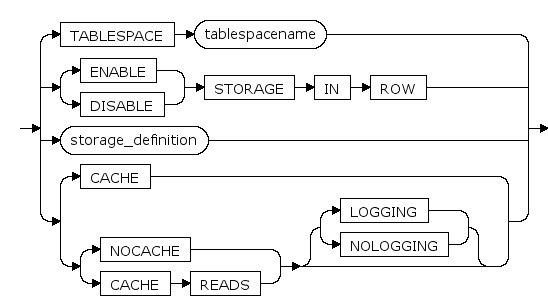
TABLESPACE tablespacename
该参数与此前的“TABLESPACE tablespacename”含义相同,此选项用于指定创建LOB列时LOB段所在的表空间。 一般情况下,当LOB段与主表所在的段位于不同的表空间时,效率较高。 每个LOB段在不同的表空间可以避免硬件设备的竞争,从而提高访问效率。
当用户未指定表空间,则LOB数据和索引均在主表的表空间内;
当用户指定了表空间,则LOB数据和索引均在指定的表空间内。
注解
存储位置还受参数 ENABLE | DISABLE STORAGE IN ROW 的影响。
ENABLE | DISABLE STORAGE IN ROW
是否允许小于等于600字节的LOB内容存储在行内。
ENABLE:允许小于等于600字节的数据存储在行内,默认值。
DISABLE:不管插入数据长度如何,系统将直接将数据存储在LOB段中。
CACHE
(暂不支持)缓存LOB页
CACHE READS
(暂不支持)读LOB时缓存,写LOB时不缓存
NOCACHE
(暂不支持)不缓存LOB页,缺省
LOGGING | NOLOGGING
该参数与此前的“LOGGING|NOLOGGIN”含义相同,此处针对于创建LOB段。选项仅在CACHE READS或NOCACHE时有效,当设置CACHE时,该选项必须为LOGGING;当设置CACHE READS或NOCACHE且未指定该属性时,该选项与LOB所在表空间的相应日志选项相同。
storage_definition
LOB段的存储参数。
INT size [ K | KB | M | MB | G | GB | T | TB ]
该参数与此前的“INT size [ K | KB | M | MB | G | GB | T | TB ]”相同,此处作用于创建LOB段。
NEXT size [ K | KB | M | MB | G | GB | T | TB ]
该参数与此前的“NEXT size [ K | KB | M | MB | G | GB | T | TB ]”相同,此处作用于创建LOB段。
MAX size [ K | KB | M | MB | G | GB | T | TB ]
该参数与此前的“MAX size [ K | KB | M | MB | G | GB | T | TB ]”相同,此处作用于创建LOB段。
PCTFREE freesize
该参数与此前的“PCTFREE freesize”相同,此处作用于创建LOB段。
PCTUSED usedsize
该参数与此前的“PCTUSED usedsize”相同,此处作用于创建LOB段。
PARTITION ... partition
分区的名。
SUBPARTITION ... subpartition
复合分区名。
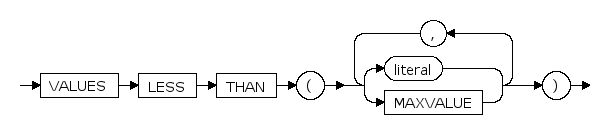
PARTITION ... MAXVALUE
分区值的最大值。
PARTITION ... DEFAULT
标识list分区中用户未指定的所有分区值。
PARTITION ... NULL
标识list分区中某分区包含空值。
PARTITION ... literal
与分区键类型匹配的常值。
PARTITION ... AT
分裂range分区表时,为新分区表指定的分区键值界限。
PARTITION ... VALUES
分裂list分区表时,为新分区指定的分区键值。
UPDATE / INVALIDATE
实时更新索引或延迟更新索引。
update_all_index_clause
index为LOCAL主分区索引,如果指定,则表示该操作更新的是该主分区索引下与基础表的子分区表相关联的子分区索引。
index_partition_description/update_index_subpartition
如果不指定,默认更新所有的局部主分区索引下与基础表的子分区表相关联的子分区索引。
LOCAL
索引的子分区数必须与基础表的子分区数相等。partition/subpartition更新子分区索引的新名称;如果不指定,则更新后的索引与基础表的子分区表的名称相同。tablespace_name表示指定子分区索引的表空间为tablespace_name。
PARTITION ... WITH / WITHOUT VALIDATION
交换分区时,是否对被交换基本表中数据进行合法性检查。
PARTITION ... INCLUDING / EXCLUDING INDEXES
交换分区时,是否交换索引。
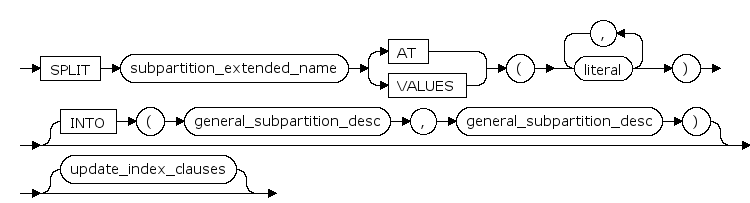
PARTITION ... SPLIT ... INTO
将分区在某个值分裂成两个分区(range分区),或分区分裂某些值成一个分区(list分区)。
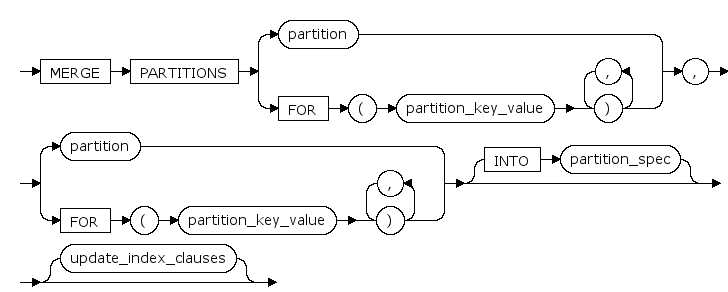
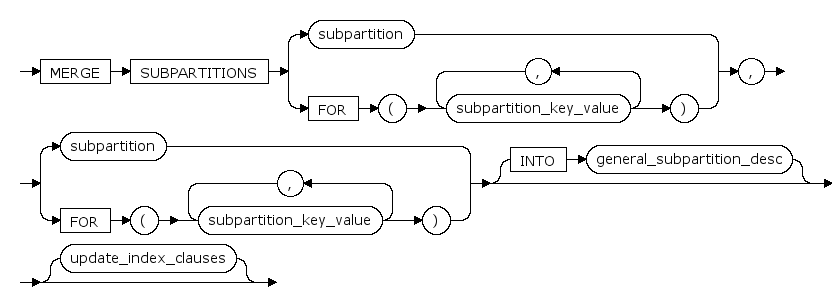
COALESCE PARTITION update_index_clauses
结合分区表时更新索引。(目前不支持为分区索引指定tablespace)
general_subpartition_desc
中只能定义table_parttioning_decription中tablespace,其他属性均不能自由定义
ENABLE | DISABLE
禁用或启用约束。
若ENABLE一个UNIQUE或PRIMARY KEY约束,将会创建一个唯一索引。
若DISABLE一个UNIQUE或PRIMARY KEY约束,该约束的唯一索引会被删除。
默认为ENABLE。
VALIDATE | NOVALIDATE
是否对已有的数据进行约束检查。
VALIDATE和NOVALIDATE的行为依赖于约束是ENABLE还是DISABLE,
如果指定了ENABLE,但没有指定VALIDATE与NOVALIDATE,默认是VALIDATE。
如果指定了DISABLE,但没有指定VALIDATE与NOVALIDATE,默认是NOVALIDATE。
{ ENABLE | DISABLE} ALL TRIGGERS
禁用或启用表上所有的触发器,不包括外键约束触发器。
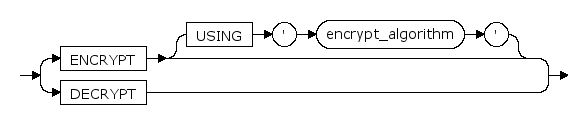
ENCRYPT | DECRYPT
设置表或列的加密模式。
ENCRYPT 设置表或列为加密模式,数据将会加密存储。
DECRYPT 设置或列表为非加密模式,数据不会被加密。
缺省时,加密模式保持不变。
注解
属性加密目前语法只支持使用ENCRYPT,不支持使用USING子句。
USING 'encrypt_algorithm'
指定加密算法。目前支持的加密算法包括:'des3' 、 'aes128' 、 'aes192' 、 'aes256' 、 'sm4'。
注解
若要添加新数据行,请使用INSERT 语句。若要删除数据行,请使用 DELETE 或 TRUNCATE TABLE 语句。若要更改现有行中的值,请使用UPDATE语句。
ALTER TABLE 语句指定的更改将立即实现。如果这些更改需要修改表中的行,ALTER TABLE 将更新这些行。ALTER TABLE 将获取表上的修改锁,以确保在更改期间其它连接不能引用该表(甚至不能引用其元数据)。对表进行的更改将记录于日志中,并且可以完全恢复。影响非常大的表中所有行的更改,比如除去一列或者用默认值添加 NOT NULL 列,可能需要较长时间才能完成,并会生成大量日志记录。如同影响大量行的 INSERT、UPDATE 或者 DELETE 语句一样,这一类 ALTER TABLE 语句也应小心使用。
当除去约束时,作为约束的一部分而创建的索引也将除去。而通过 CREATE INDEX 创建的索引必须使用 DROP INDEX 语句来除去。
当在现有列上添加新 PRIMARY KEY 或 UNIQUE 约束时,该列中的数据必须唯一。如果存在重复值,ALTER TABLE 语句将失败.每个 PRIMARY KEY 和 UNIQUE 约束都将生成一个索引。
ALTER COLUMN TYPE:
如果该列在所有行上均为null(即列上没有数据),字段的原类型和目标类型可以是除大对象以外的任何类型。
列上有数据时,数据库将尝试对列上的所有数据进行转化(从原类型到目标类型)。只要有一行数据不能转化为目标类型,修改就会失败。注意:转换数据类型时将使用e类型转换(参考“数据类型的强制转化规则”),该转换会忽略可能的精度丢失。
- 如果列上有默认值,数据库将会检查默认值表达式能否作为新类型的默认值,如果不能,修改将会失败。该检查与设置默认值时所做的检查是一致的。
如果列上有check约束,该约束将会被重建。如果目标类型不能用于约束表达式或转换后的数据不符合约束,修改将会失败。
如果列上有索引,该索引将会被重建。如果目标类型不能创建对应类型的索引或转换后的数据不能建立索引,修改将会失败。
如果列上有primary key或unique约束,该约束将会被重建。如果转换后的数据不符合约束,修改将会失败。
如果列属于外键(或外键引用的键),只有新类型与被引用列(或引用列)类型兼容时才可以进行修改。
如果目标类型为域(domain)类型,数据库将会检查domain类型本身的约束,如果列上的数据不符合domain约束,修改将会失败。
ALTER TABLE PARTITION:
- 通过添加分区操作可以增加分区表中的分区数,目前本操作只支持Range、List分区;需要注意的是,在添加Range分区时,新添加分区的分区键值需要大于现有分区的分区键值的最高界限,即必须位于所有分区之后。
通过删除分区操作可以减少分区表中的分区数,本操作只支持Range、List分区。
通过交换分区操作可以将指定分区同结构相同的表相交换,从而更新相应分区中的数据;可以通过参数来指定是否强制检查交换数据的合法性,也可以通过参数来指定是否交换双方的索引。
通过移动分区操作可以移动分区至不同的表空间或整理碎片。
通过截断分区操作可以快速删除分区中的数据。
通过分裂分区操作可以将某些数据过大的分区按给定的分区值分裂为两个小分区;Range分区表的分裂操作可以实现在分区表的中间位置添加新分区,从而解决添加分区操作只可以添加在最后位置的问题,该操作不支持Hash分区。
通过合并分区操作可以将两个数据过小的分区合并为一个大分区;Range分区表的合并操作要求待合并的两个分区顺序上必须相邻,该操作不支持Hash 分区。
修改默认属性值影响新创建的一级或二级子分区。如果被修改对象不存在子分区,不可以进行默认值修改。换句话说,一级分区表的一级子分区不支持默认值修改;二级分区表的二级子分区不支持默认值修改;非分区表不支持默认值修改。
另外,关于更新索引参数的指定,目前只支持实时更新索引,暂不支持延迟更新索引。
如果要更新的表为临时表,则遵循以下原则:
- 每一个会话第一次向临时表中插入数据时会创建一个与会话相关联的数据段,即临时表的实例化(通过视图v_sys_temp_instance可以查看当前所有的临时表实例),临时表会与该会话进行绑定,当事务或会话结束时临时表与该事务或会话的绑定将会解除。
2. 如果需要对临时表进行ADD COLUMN、DROP COLUMN、ALTER COLUMN TYPE、ALTER COLUMN SET NOT NULL和ADD CONSTRAINT等更新操作时,临时表不能与任何事务或会话绑定。
3. 如果需要对临时表进行ALTER COLUMN DEFAULT、ALTER COLUMN DROP NOT NULL、RENAME COLUMN、RENAME TO、 DROP CONSTRAINT和OWNER TO等更新操作时,临时表不能与其他事务或会话绑定,只与本事务或会话自身绑定时可以进行这些更新操作。
4. 不支持在临时表上进行LOCK、BLOCK | TUPLE、REBUILD、COMPRESS和PARTITION操作。
- 全局临时表支持修改存储参数,但是因事务级临时表可能需要回滚,所以不支持NOLOGGING参数;本地临时表没有限制。
示例¶
示例1: 添加列
-- 清理环境
DROP TABLE tab1 CASCADE;
-- 创建表并插入数据
CREATE TABLE tab1 (a INT);
INSERT INTO tab1 VALUES(100);
INSERT INTO tab1 VALUES(200);
INSERT INTO tab1 VALUES(300);
SELECT * FROM tab1 ORDER BY a;
A(int) |
------------
100 |
------------
200 |
------------
300 |
总数目:3
-- 添加一个允许空值的列, 没有通过 DEFAULT 定义提供值, 允许列值为 NULL
ALTER TABLE tab1 ADD b VARCHAR(20) NULL;
-- 各行的新列中的值将为 NULL
SELECT * FROM tab1 ORDER BY a;
A(int) |B(varchar) |
----------------------------
100 |null |
----------------------------
200 |null |
----------------------------
300 |null |
总数目:3
-- 删除表
DROP TABLE tab1;
示例2: 删除列/多列
-- 清理环境
DROP TABLE tab2 CASCADE;
-- 创建表并插入数据
CREATE TABLE tab2 (a INT, b VARCHAR(20), c number(10), d text);
INSERT INTO tab2 VALUES(100, 'aaa', 100, 'AAA');
INSERT INTO tab2 VALUES(200, 'bbb', 200, 'BBB');
INSERT INTO tab2 VALUES(300, 'ccc', 300, 'CCC');
SELECT * FROM tab2 ORDER BY a;
A(int) |B(varchar) |C(numeric) |D(text) |
---------------------------------------------------------
100 |aaa |100 |AAA |
---------------------------------------------------------
200 |bbb |200 |BBB |
---------------------------------------------------------
300 |ccc |300 |CCC |
总数目:3
-- 删除列
ALTER TABLE tab2 DROP COLUMN b;
-- 查询删除列后表中数据
SELECT * FROM tab2 ORDER BY a;
A(int) |C(numeric) |D(text) |
-----------------------------------------
100 |100 |AAA |
-----------------------------------------
200 |200 |BBB |
-----------------------------------------
300 |300 |CCC |
总数目:3
-- 删除多列
ALTER TABLE tab2 DROP COLUMN (c, d);
-- 查询删除多列后表中数据
SELECT * FROM tab2 ORDER BY a;
A(int) |
------------
100 |
------------
200 |
------------
300 |
总数目:3
-- 添加列
ALTER TABLE tab2 ADD c VARCHAR(20) NULL;
-- 查询添加列后的表中数据
SELECT * FROM tab2 ORDER BY a;
A(int) |C(varchar) |
----------------------------
100 |null |
----------------------------
200 |null |
----------------------------
300 |null |
总数目:3
--删除列
ALTER TABLE tab2 DROP COLUMN (c);
-- 查询删除列后表中数据
SELECT * FROM tab2 ORDER BY a;
A(int) |
------------
100 |
------------
200 |
------------
300 |
总数目:3
-- 删除表
DROP TABLE tab2;
示例3: 添加具有约束的列(以 UNIQUE 约束为例)
-- 清理环境
DROP TABLE tab3 CASCADE;
-- 创建表并插入数据
CREATE TABLE tab3 (a INT);
INSERT INTO tab3 VALUES(100);
INSERT INTO tab3 VALUES(200);
INSERT INTO tab3 VALUES(300);
SELECT * FROM tab3 ORDER BY a;
A(int) |
------------
100 |
------------
200 |
------------
300 |
总数目:3
-- 添加具有 UNIQUE 约束的列
ALTER TABLE tab3 ADD b VARCHAR(20) NULL CONSTRAINT cons_unique UNIQUE;
-- 各行的新列中的值将为 NULL
SELECT * FROM tab3 ORDER BY a;
A(int) |B(varchar) |
----------------------------
100 |null |
----------------------------
200 |null |
----------------------------
300 |null |
总数目:3
-- 插入违反 UNIQUE 约束的数据
INSERT INTO tab3 VALUES(400, 'aaa');
INSERT INTO tab3 VALUES(500, 'aaa');
ERROR, 不能向索引CONS_UNIQUE中插入重复键值(B) = (aaa)
-- (500, 'aaa') 未被插入
SELECT * FROM tab3 ORDER BY a;
A(int) |B(varchar) |
----------------------------
100 |null |
----------------------------
200 |null |
----------------------------
300 |null |
----------------------------
400 |aaa |
总数目:4
-- 删除表
DROP TABLE tab3;
示例4: 添加约束(以 CHECK 约束为例)
-- 清理环境
DROP TABLE tab4 CASCADE;
-- 创建表并插入数据
CREATE TABLE tab4 (a INT);
INSERT INTO tab4 VALUES(100);
INSERT INTO tab4 VALUES(200);
INSERT INTO tab4 VALUES(300);
SELECT * FROM tab4 ORDER BY a;
A(int) |
------------
100 |
------------
200 |
------------
300 |
总数目:3
-- 添加 CHECK 约束
-- 表中存在违反 CHECK 约束的数据, 添加约束失败
ALTER TABLE tab4 ADD CONSTRAINT cons_check CHECK (a < 300);
ERROR, 约束限制, AlterTableAddConstraint: rejected due to CHECK constraint CONS_CHECK
-- 数据未发生变化
SELECT * FROM tab4 ORDER BY a;
A(int) |
------------
100 |
------------
200 |
------------
300 |
总数目:3
-- 可以插入 "违反 CHECK 约束" 的数据(此时约束并不存在)
INSERT INTO tab4 VALUES(400);
SELECT * FROM tab4 ORDER BY a;
A(int) |
------------
100 |
------------
200 |
------------
300 |
------------
400 |
总数目:4
-- 删除 "违反 CHECK 约束" 的数据(此时约束并不存在)
DELETE FROM tab4 WHERE a >= 300;
-- 添加 CHECK 约束
-- 表中不存在违反 CHECK 约束的数据, 添加约束成功
ALTER TABLE tab4 ADD CONSTRAINT cons_check CHECK (a < 300);
-- 数据未发生变化
SELECT * FROM tab4 ORDER BY a;
A(int) |
------------
100 |
------------
200 |
总数目:2
-- 无法插入 违反 CHECK 约束 的数据(此时约束已存在)
INSERT INTO tab4 VALUES(400);
ERROR, INSERT的数据违反了关系TAB4上的约束CONS_CHECK
-- 数据(400)未被插入
SELECT * FROM tab4 ORDER BY a;
A(int) |
------------
100 |
------------
200 |
总数目:2
-- 删除表
DROP TABLE tab4;
示例5: 添加多个列(带有约束)
-- 清理环境
DROP TABLE tab5 CASCADE;
-- 创建表并插入数据
CREATE TABLE tab5 (a INT UNIQUE);
-- 添加多个列(带有约束)
ALTER TABLE tab5 ADD
(
b INT CONSTRAINT cons_b_pk PRIMARY KEY, -- 主键
c INT CONSTRAINT cons_c_fk REFERENCES tab5(a), -- 外键
d INT CONSTRAINT cons_d_ck CHECK (d > 9), -- CHECK 约束
e INT DEFAULT 505 -- DEFAULT
);
-- 符合各项约束, 插入数据成功
INSERT INTO tab5 VALUES(100, 1000, 100, 10, 10000);
SELECT * FROM tab5 ORDER BY b;
A(int) |B(int) |C(int) |D(int) |E(int) |
------------------------------------------------------------
100 |1000 |100 |10 |10000 |
总数目:1
-- 违反主键约束, 插入失败
INSERT INTO tab5 VALUES(200, 1000, 100, 20, 20000);
ERROR, 不能向索引CONS_B_PK中插入重复键值(B) = (1000)
SELECT * FROM tab5 ORDER BY b;
A(int) |B(int) |C(int) |D(int) |E(int) |
------------------------------------------------------------
100 |1000 |100 |10 |10000 |
总数目:1
-- 违反外键约束, 插入失败
INSERT INTO tab5 VALUES(300, 3000, 333, 30, 30000);
ERROR, CONS_C_FK referential integrity violation - key referenced from TAB5 not found in TAB5
SELECT * FROM tab5 ORDER BY b;
A(int) |B(int) |C(int) |D(int) |E(int) |
------------------------------------------------------------
100 |1000 |100 |10 |10000 |
总数目:1
-- 违反 CHECK 约束, 插入失败
INSERT INTO tab5 VALUES(400, 4000, 400, 4, 40000);
ERROR, INSERT的数据违反了关系TAB5上的约束CONS_D_CK
SELECT * FROM tab5 ORDER BY b;
A(int) |B(int) |C(int) |D(int) |E(int) |
------------------------------------------------------------
100 |1000 |100 |10 |10000 |
总数目:1
-- 符合各项约束, 使用 DEFAULT 值, 插入成功
INSERT INTO tab5(a, b, c, d) VALUES(500, 5000, 500, 50);
-- 新插入数据 e 列值为默认值 —— 505
SELECT * FROM tab5 ORDER BY b;
A(int) |B(int) |C(int) |D(int) |E(int) |
------------------------------------------------------------
100 |1000 |100 |10 |10000 |
------------------------------------------------------------
500 |5000 |500 |50 |505 |
总数目:2
-- 删除表
DROP TABLE tab5;
示例6: 添加列(有默认值且可为空)
-- 清理环境
DROP TABLE tab6 CASCADE;
-- 创建表并插入数据
CREATE TABLE tab6 (a INT);
INSERT INTO tab6 VALUES(1000);
INSERT INTO tab6 VALUES(2000);
INSERT INTO tab6 VALUES(3000);
SELECT * FROM tab6 ORDER BY a;
A(int) |
------------
1000 |
------------
2000 |
------------
3000 |
总数目:3
-- 添加列(有默认值且可为空)
ALTER TABLE tab6 ADD b VARCHAR(20) NULL DEFAULT 'df_value';
-- 原有数据 b 列是默认值 'df_value'
SELECT * FROM tab6 ORDER BY a;
A(int) |B(varchar) |
----------------------------
1000 |df_value |
----------------------------
2000 |df_value |
----------------------------
3000 |df_value |
总数目:3
-- 新插入数据使用默认值
INSERT INTO tab6(a) VALUES(4000);
SELECT * FROM tab6 ORDER BY a;
A(int) |B(varchar) |
----------------------------
1000 |df_value |
----------------------------
2000 |df_value |
----------------------------
3000 |df_value |
----------------------------
4000 |df_value |
总数目:4
-- 新插入数据使用指定值
INSERT INTO tab6 VALUES(5000, 'aaa');
SELECT * FROM tab6 ORDER BY a;
A(int) |B(varchar) |
----------------------------
1000 |df_value |
----------------------------
2000 |df_value |
----------------------------
3000 |df_value |
----------------------------
4000 |df_value |
----------------------------
5000 |aaa |
总数目:5
-- 删除表
DROP TABLE tab6;
示例7: 添加列(大对象类型 —— CLOB 、 BLOB)
-- 清理环境
DROP TABLE tab7 CASCADE;
DROP TABLESPACE test;
CREATE TABLESPACE test DATAFILE 'testdbf.dbf';
-- 创建表并插入数据
CREATE TABLE tab7 (id INT);
-- 添加 1 个 LOB 类型列, 不指定 LOB 列任何参数
ALTER TABLE tab7 ADD (a BLOB);
-- 添加 2 个 LOB 类型列
-- 两个 LOB 列分别存储在两个不同的 LOB 段中
-- 段名由系统指定, 两个 LOB 列共享存储参数
ALTER TABLE tab7 ADD (b BLOB, c BLOB)
LOB(b, c) STORE AS (TABLESPACE users ENABLE STORAGE IN ROW CACHE);
-- 添加 2 个 LOB 类型列, 分别指定 LOB 段名等参数
ALTER TABLE tab7 ADD (bb BLOB, cc CLOB)
LOB(bb) STORE AS lobseg1
LOB(cc) STORE AS lobseg2(TABLESPACE test DISABLE STORAGE IN ROW NOCACHE LOGGING);
-- 清理环境
DROP TABLE tab7;
DROP TABLESPACE test;
示例8: 修改列类型(列上没有数据)
-- 清理环境
DROP TABLE tab8 CASCADE;
-- 创建表
CREATE TABLE tab8 (id INT);
-- 修改列类型(列上没有数据)
ALTER TABLE tab8 ALTER TYPE id NUMBER;
-- 删除表
DROP TABLE tab8;
示例9: 修改列类型(列上有数据)
-- 清理环境
DROP TABLE tab9 CASCADE;
-- 创建表
CREATE TABLE tab9 (id CHAR(10));
-- 插入数据(可以转换为 INT 类型值)
INSERT INTO tab9 VALUES('100');
SELECT * FROM tab9 ORDER BY id;
ID(char) |
--------------
100 |
总数目:1
-- 修改列类型 CHAR(10) 转为 INT, 列数据可以转换到目标类型
ALTER TABLE tab9 ALTER TYPE id INT;
SELECT * FROM tab9 ORDER BY id;
ID(int) |
-------------
100 |
总数目:1
-- 修改列类型 INT 转为 CHAR(10), 列数据可以转换到目标类型
ALTER TABLE tab9 ALTER TYPE id CHAR(10);
SELECT * FROM tab9 ORDER BY id;
ID(char) |
--------------
100 |
总数目:1
-- 更新数据(不可转换为 INT 类型值)
UPDATE tab9 SET id = 'xvf';
SELECT * FROM tab9 ORDER BY id;
ID(char) |
--------------
xvf |
总数目:1
-- 修改列类型 CHAR(10) 转为 INT, 列数据不可转换到目标类型
ALTER TABLE tab9 ALTER TYPE id INT;
ERROR, 错误的数值格式 'xvf'
SELECT * FROM tab9 ORDER BY id;
ID(char) |
--------------
xvf |
总数目:1
-- 删除表
DROP TABLE tab9;
示例10: 修改列类型(忽略精度损失)
-- 清理环境
DROP TABLE tab10 CASCADE;
-- 创建表并插入数据
CREATE TABLE tab10 (id NUMBER);
INSERT INTO tab10 VALUES(3.14);
SELECT * FROM tab10 ORDER BY id;
ID(numeric) |
-----------------
3.14 |
总数目:1
-- 修改列类型 NUMBER 转为 INT, 忽略精度损失
ALTER TABLE tab10 ALTER TYPE id INT;
SELECT * FROM tab10 ORDER BY id;
ID(int) |
-------------
3 |
总数目:1
-- 删除表
DROP TABLE tab10;
示例11: 修改列类型(列上有默认值)
-- 清理环境
DROP TABLE tab11 CASCADE;
-- 创建表
CREATE TABLE tab11 (id INT, a NUMBER DEFAULT 3.14);
-- 修改列类型 NUMBER 转为 VARCHAR(20)
-- 列上有默认值, 默认值可以转为目标类型
ALTER TABLE tab11 ALTER TYPE a VARCHAR(20);
-- 新插入数据使用默认值
INSERT INTO tab11(id) VALUES(1);
SELECT * FROM tab11 ORDER BY id;
ID(int) |A(varchar) |
-----------------------------
1 |3.14 |
总数目:1
-- 新插入数据使用指定值
INSERT INTO tab11 VALUES(2, 'xvf');
SELECT * FROM tab11 ORDER BY id;
ID(int) |A(varchar) |
-----------------------------
1 |3.14 |
-----------------------------
2 |xvf |
总数目:2
-- 修改列类型 VARCHAR(20) 转为 DATE
-- 列上有默认值, 默认值不可转为目标类型, 修改失败
ALTER TABLE tab11 ALTER TYPE a DATE;
ERROR, ALTER TABLE: default for column "A" cannot be cast to type "DATE"
-- 去掉列上的 DEFAULT 值
ALTER TABLE tab11 ALTER COLUMN a DROP DEFAULT;
SELECT * FROM tab11;
ID(int) |A(varchar) |
-----------------------------
1 |3.14 |
-----------------------------
2 |xvf |
总数目:2
-- 列数据置为 NULL
UPDATE tab11 SET a = NULL;
SELECT * FROM tab11;
ID(int) |A(varchar) |
-----------------------------
1 |null |
-----------------------------
2 |null |
总数目:2
-- 修改列类型 VARCHAR(20) 转为 DATE
ALTER TABLE tab11 ALTER TYPE a DATE;
-- 删除表
DROP TABLE tab11;
示例12: 修改列类型(列上有 CHECK 约束)
-- 清理环境
DROP TABLE tab12 CASCADE;
-- 创建表并插入数据
CREATE TABLE tab12 (id INT, a NUMBER CONSTRAINT cons_ck CHECK(a > 3));
INSERT INTO tab12 VALUES(1, 3.14);
SELECT * FROM tab12 ORDER BY id;
ID(int) |A(numeric) |
-----------------------------
1 |3.14 |
总数目:1
-- 修改列类型 NUMBER 转为 VARCHAR(20)
-- 列上有 CHECK 约束, 转换后的数据符合约束
ALTER TABLE tab12 ALTER TYPE a VARCHAR(20);
SELECT * FROM tab12 ORDER BY id;
ID(int) |A(varchar) |
-----------------------------
1 |3.14 |
总数目:1
-- 删除表
DROP TABLE tab12;
示例13: 修改列类型(列上有索引)
-- 清理环境
DROP INDEX idx13 CASCADE;
DROP TABLE tab13 CASCADE;
-- 创建表并插入数据
CREATE TABLE tab13 (id INT, a NUMBER);
INSERT INTO tab13 VALUES(1, 3.14);
INSERT INTO tab13 VALUES(2, 10);
SELECT * FROM tab13 ORDER BY id;
ID(int) |A(numeric) |
-----------------------------
1 |3.14 |
-----------------------------
2 |10 |
总数目:2
-- 创建索引
CREATE INDEX idx13 ON tab13(a);
-- 修改列类型 NUMBER 转为 CHAR(20)
ALTER TABLE tab13 ALTER TYPE a CHAR(20);
SELECT * FROM tab13 ORDER BY id;
ID(int) |A(char) |
--------------------------
1 |3.14 |
| |
--------------------------
2 |10 |
| |
总数目:2
-- 删除索引和表
DROP INDEX idx13;
DROP TABLE tab13;
示例14: 修改列类型(目标类型为域类型 —— domain)
-- 清理环境
DROP TABLE tab14 CASCADE;
DROP DOMAIN dm1 CASCADE;
-- 创建域类型
CREATE DOMAIN dm1 INT NOT NULL;
-- 创建表
CREATE TABLE tab14 (id INT, a NUMBER);
-- 插入数据(不符合转换目标类型dm1 NOT NULL 约束)
INSERT INTO tab14 VALUES(1, NULL);
SELECT * FROM tab14 ORDER BY id;
ID(int) |A(numeric) |
-----------------------------
1 |null |
总数目:1
-- 修改列类型 NUMBER 转为 dm1, 修改失败
ALTER TABLE tab14 ALTER TYPE a dm1;
ERROR, 域 DM1 不允许空值
SELECT * FROM tab14 ORDER BY id;
ID(int) |A(numeric) |
-----------------------------
1 |null |
总数目:1
-- 更新列数据, 符合 NOT NULL
UPDATE tab14 SET a = 3.14;
-- 修改列类型 NUMBER 转为 dm1, 修改成功
ALTER TABLE tab14 ALTER TYPE a dm1;
SELECT * FROM tab14 ORDER BY id;
ID(int) |A(DM1) |
-------------------------
1 |3 |
总数目:1
-- 删除域和表
DROP TABLE tab14;
DROP DOMAIN dm1;
示例15: 禁用/启用约束
-- 清理环境
DROP TABLE tab15 CASCADE;
-- 创建表
CREATE TABLE tab15
(
id INTEGER,
a INT,
b VARCHAR(30),
c INT CONSTRAINT cons_ck_c CHECK(c < 55),
d INT,
e INT,
PRIMARY KEY(id, a),
UNIQUE(d, e)
) DISABLE PRIMARY KEY;
-- 查看约束状态(未查询 SYS_CONSTRAINT 全部字段信息)
SELECT CONNAME, CONTYPE, CONENABLE, CONVALIDATE FROM SYS_CONSTRAINT, SYS_CLASS
WHERE SYS_CONSTRAINT.CONRELID = SYS_CLASS.OID AND SYS_CLASS.RELNAME = 'TAB15'
ORDER BY CONNAME;
CONNAME(name) |CONTYPE("CHAR") |CONENABLE(boolean) |CONVALIDATE(boolean) |
------------------------------------------------------------------------------------------
CONS_CK_C |c |true |true |
------------------------------------------------------------------------------------------
TAB15_D_KEY |u |true |true |
------------------------------------------------------------------------------------------
TAB15_PKEY |p |false |false |
总数目:3
-- 启用禁用约束
ALTER TABLE tab15 DISABLE VALIDATE UNIQUE(d, e) DISABLE CONSTRAINT cons_ck_c ENABLE PRIMARY KEY;
-- 查看约束状态(未查询 SYS_CONSTRAINT 全部字段信息)
SELECT CONNAME, CONTYPE, CONENABLE, CONVALIDATE FROM SYS_CONSTRAINT, SYS_CLASS
WHERE SYS_CONSTRAINT.CONRELID = SYS_CLASS.OID AND SYS_CLASS.RELNAME = 'TAB15'
ORDER BY CONNAME;
CONNAME(name) |CONTYPE("CHAR") |CONENABLE(boolean) |CONVALIDATE(boolean) |
------------------------------------------------------------------------------------------
CONS_CK_C |c |false |false |
------------------------------------------------------------------------------------------
TAB15_D_KEY |u |false |true |
------------------------------------------------------------------------------------------
TAB15_PKEY |p |true |true |
总数目:3
-- 删除表
DROP TABLE tab15;
示例16: 修改缓存方式
-- 清理环境
DROP INDEX idx16 CASCADE;
DROP TABLE tab16 CASCADE;
-- 创建表
CREATE TABLE tab16
(
id INT,
a VARCHAR(10),
b INT,
PRIMARY KEY(id, b) USING INDEX T1_P BUFFER_POOL KEEP
) OVERFLOW START 1;
-- 创建索引
CREATE UNIQUE INDEX idx16 ON tab16(id, a);
-- 修改缓存方式
ALTER TABLE tab16 ADD UNIQUE(id, a) USING INDEX idx16 BUFFER_POOL RECYCLE;
-- 删除表
DROP TABLE tab16;
示例17: 修改分区(以列表分区为例)
-- 清理环境
DROP TABLE ex_tab17 CASCADE;
DROP TABLE tab17 CASCADE;
DROP TABLESPACE ts17;
-- 创建表空间
CREATE TABLESPACE ts17 DATAFILE 'ts17.data' SIZE 5m AUTOEXTEND ON NEXT 2m;
-- 创建 list 分区表
CREATE TABLE tab17 (id INT, a VARCHAR(30))
PARTITION BY LIST (a)
(
PARTITION asia VALUES ('CHINA', 'THAILAND'),
PARTITION europe VALUES ('GERMANY', 'ITALY', 'SWITZERLAND'),
PARTITION america VALUES ('AMERICA')
);
-- 添加分区
ALTER TABLE tab17 ADD PARTITION south_asia VALUES('INDIA');
ALTER TABLE tab17 ADD PARTITION rest VALUES(DEFAULT);
-- 删除分区
ALTER TABLE tab17 DROP PARTITION south_asia;
-- 移动分区
ALTER TABLE tab17 MOVE PARTITION asia TABLESPACE ts17;
-- 截断分区
ALTER TABLE tab17 TRUNCATE PARTITION rest;
-- 交换分区
CREATE TABLE ex_tab17 (id INT, a VARCHAR(30));
ALTER TABLE tab17 EXCHANGE PARTITION america WITH TABLE ex_tab17 INCLUDING INDEXES WITHOUT VALIDATION;
-- 分裂分区
ALTER TABLE tab17 SPLIT PARTITION rest VALUES ('MEXICO', 'COLOMBIA')
INTO (PARTITION south, PARTITION rest) UPDATE GLOBAL INDEXES;
-- 合并分区
ALTER TABLE tab17 MERGE PARTITIONS asia, rest INTO PARTITION rest UPDATE GLOBAL INDEXES;
-- 删除表和表空间
DROP TABLE ex_tab17 CASCADE;
DROP TABLE tab17 CASCADE;
DROP TABLESPACE ts17;
示例18: 修改自增列
DROP TABLE tab18;
CREATE TABLE tab18(a INT AUTO_INCREMENT UNIQUE, b INT);
INSERT INTO tab18 VALUES(NULL, 1);
SELECT * FROM tab18 ORDER BY b;
A(int) |B(int) |
------------------------
1 |1 |
总数目:1
--自增列数据类型只能修改为整型或浮点型
ALTER TABLE tab18 ALTER TYPE a BOOL AUTO_INCREMENT;
ERROR, 自增列(AUTO_INCREMENT)的数据类型应该使用整型或浮点类型
ALTER TABLE tab18 ALTER TYPE a FLOAT AUTO_INCREMENT;
INSERT INTO tab18 VALUES(NULL, 2);
SELECT * FROM tab18 ORDER BY b;
A(float) |B(int) |
--------------------------
1 |1 |
--------------------------
2 |2 |
总数目:2
--自增列修改为普通列
ALTER TABLE tab18 ALTER TYPE a FLOAT;
--插入NULL,而不是内部自增的值
INSERT INTO tab18 VALUES(NULL, 3);
SELECT * FROM tab18 ORDER BY b;
A(float) |B(int) |
--------------------------
1 |1 |
--------------------------
2 |2 |
--------------------------
null |3 |
总数目:3
--不能修改普通列为自增列
ALTER TABLE tab18 ALTER TYPE a FLOAT AUTO_INCREMENT;
ERROR, 无法删除 其他对象依赖这个先删除, Cannot drop index SYSDBA.TAB18_A_KEY because constraint TAB18_A_KEY on table SYSDBA.TAB18 requires it
You may drop constraint TAB18_A_KEY on table SYSDBA.TAB18 instead
DROP TABLE tab18;
CREATE TABLE tab18(a INT);
--添加自增列
ALTER TABLE tab18 ADD COLUMN (b INT AUTO_INCREMENT CONSTRAINT PK PRIMARY KEY);
INSERT INTO tab18 VALUES(1, NULL);
SELECT * FROM tab18 ORDER BY a;
A(int) |B(int) |
------------------------
1 |1 |
总数目:1
--再添加一列,表中已有自增列,失败
ALTER TABLE tab18 ADD COLUMN (c INT AUTO_INCREMENT unique);
ERROR, 表只能有一列自增列
ALTER TABLE tab18 DROP CONSTRAINT PK;
ERROR, 不能删除仅有的仅包括自增列或自增列为第一列的索引约束
DROP TABLE tab18;
示例19: 删除主键
DROP TABLE tab19;
CREATE TABLE tab19(a INT PRIMARY KEY, b INT);
INSERT INTO tab19 VALUES(1,12);
INSERT INTO tab19 VALUES(2,13);
INSERT INTO tab19 VALUES(1,12);
ERROR, 不能向索引TAB19_PKEY中插入重复键值(A) = (1)
--删除主键
ALTER TABLE tab19 DROP PRIMARY KEY;
INSERT INTO tab19 VALUES(1,12);
SELECT * FROM tab19 ORDER BY a;
A(int) |B(int) |
------------------------
1 |12 |
------------------------
1 |12 |
------------------------
2 |13 |
总数目:3
示例20: 重建表及其索引并按照某一列或者几列排序
CREATE TABLE tab20(a INT PRIMARY KEY, b INT);
INSERT INTO tab20 VALUES(1,12);
INSERT INTO tab20 VALUES(2,13);
--重建表及其索引并按照表内指定的列进行排序
ALTER TABLE tab20 REBUILD CLUSTER (a);
ALTER TABLE tab20 REBUILD CLUSTER (a, b);
SELECT * FROM tab20;
A(int) |B(int) |
------------------------
1 |12 |
------------------------
2 |13 |
总数目:2
DROP TABLE tab20;
示例21:将溢出数据段按索引组织添加到指定的表中
ALTER SYSTEM SET ENCRYPTION KEY IDENTIFIED BY 'Qwertyuiopasdfg!';
ALTER SYSTEM SET ENCRYPTION WALLET OPEN IDENTIFIED BY 'Qwertyuiopasdfg!';
CREATE TABLE tab21(a INT, b INT PRIMARY KEY)
INIT 2M NEXT 2M BUFFER_POOL KEEP
OVERFLOW START 1;
INSERT INTO tab21 VALUES(2,12);
INSERT INTO tab21 VALUES(3,13);
--将溢出数据段按索引组织添加到指定的表中
ALTER TABLE tab21 REBUILD INITRANS 8 overflow MAXSIZE UNLIMITED STORAGE
(INITIAL 8 NEXT 8 ) BUFFER_POOL keep encrypt USING 'sm4';
SELECT * FROM tab21;
A(int) |B(int) |
------------------------
2 |12 |
------------------------
3 |13 |
总数目:2
DROP TABLE tab21;
示例22:修改列类型(使用 IF EXISTS 选项)
-- 清理环境
DROP TABLE tab22 CASCADE;
-- 使用 IF EXISTS 选项修改列类型 INT 转为 CHAR(10) (不会修改并且不报错)
ALTER TABLE IF EXISTS tab22 ALTER TYPE id CHAR(10);
-- 创建表
CREATE TABLE tab22 (id CHAR(10));
-- 修改列类型 CHAR(10) 转为 INT,
ALTER TABLE tab22 ALTER TYPE id INT;
-- 使用 IF EXISTS 选项修改列类型 INT 转为 CHAR(10)
ALTER TABLE IF EXISTS tab22 ALTER TYPE id CHAR(10);
-- 删除表
DROP TABLE tab22;
示例23:删除列类型(使用默认 RESTRICT 选项)
-- 清理环境
DROP TABLE tab23 CASCADE;
DROP TABLE tab24 CASCADE;
-- 创建表
CREATE TABLE tab23 (a INT PRIMARY KEY, b INT);
CREATE TABLE tab24 (a INT PRIMARY KEY, b INT FOREIGN KEY REFERENCES tab23(a));
-- 存在约束,删除列失败(若要删除使用CASCADE)
ALTER TABLE tab23 DROP a;
ERROR, 删除失败,table SYSDBA.TAB23 column A 被其他对象所依赖. 如有需要,可以使用 DROP ... CASCADE 语法对依赖对象进行级联删除
DROP TABLE tab23 CASCADE;
DROP TABLE tab24 CASCADE;
示例24: 修改列类型(列加密)
DROP TABLE tab25;
-- 表和属性都不加密时,alter时指定属性加密
CREATE TABLE tab25(a VARCHAR(100),b TEXT);
ALTER TABLE tab25 MODIFY B TEXT ENCRYPT;
DROP TABLE tab25;
-- 属性加密时,alter时指定属性不加密
CREATE TABLE tab25(a VARCHAR(100),b VARCHAR(100) ENCRYPT);
ALTER TABLE tab25 MODIFY B VARCHAR(100);
DROP TABLE tab25;