




GROUP_CONCAT¶
说明¶
将同一个分组中的值连接起来,返回一个字符串结果。


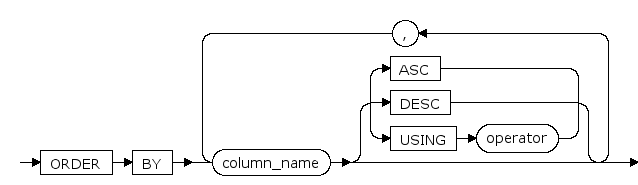


参数¶
DISTINCT
重复的数据只显示一次,使用DISTINCT关键字时可以指定分隔符但不允许添加addtion_expr。
expr
一个表达式,可以为列名或数字。为列名时若使用了GROUP BY字句,可以以table_name.column_name指定表和列。
order_by_clause
一个排序语句,此排序用于组内排序。
column_type
expr的类型,如text,int
addtion_expr
附加字符,在expr后连接指定字符。
seperator_expr
分隔符,默认为逗号。需要使用其他分隔符时需要以SAPARATOR关键字声明。
group_expr
GROUP BY子句对输入按指定的表达式序列进行分组。 形如GROUP BY expr1,具体可以参考数据库开发手册/SQL命令/SQL命令列表/SELECT: GROUP BY 节。
返回值¶
group_expr为空时返回一个字符串结果,该结果由分组中的值连接组合而成。 否则根据group_expr将结果分组以表格形式返回。
示例¶
示例1: 分组显示字符串
-- 清理环境
DROP TABLE tab1 CASCADE;
-- 创建表并插入数据
CREATE TABLE tab1(id int,a varchar(10),b char(10),c text);
INSERT INTO tab1 VALUES(1,'1_1','1_1','1_1');
INSERT INTO tab1 VALUES(1,'1_1','1_2','1_2');
INSERT INTO tab1 VALUES(1,'1_1','1_3','1_3');
INSERT INTO tab1 VALUES(2,'2_1','2_1','2_1');
INSERT INTO tab1 VALUES(2,'2_2','2_1','2_2');
INSERT INTO tab1 VALUES(2,'2_3','2_1','2_3');
INSERT INTO tab1 VALUES(3,'3_1','3_1','3_1');
INSERT INTO tab1 VALUES(3,'3_2','3_2','3_1');
INSERT INTO tab1 VALUES(3,'3_3','3_3','3_1');
-- 以'%'为分隔符,将表tab1中字段a的值在同一行打印出来
SELECT INFO_SCHEM.GROUP_CONCAT(A SEPARATOR '%') FROM TAB1;
GROUP_CONCAT(text) |
------------------------
1_1%1_1%1_1%2_1%2_2%2_3%|
3_1%3_2%3_3 |
总数目:1
-- 以默认分隔符分隔,将表tab1中字段a的值后加上字符`%`在同一行打印出来
select info_schem.group_concat(a ,'%') from tab1;
GROUP_CONCAT(text) |
------------------------
1_1%,1_1%,1_1%,2_1%,2_2%|
,2_3%,3_1%,3_2%,3_3% |
总数目:1
-- 以id分组,把a,b,c字段的值分别在同一行打印出来
SELECT GROUP_CONCAT(a),GROUP_CONCAT(b),GROUP_CONCAT(c) FROM tab1 GROUP BY id ORDER BY id;
GROUP_CONCAT(text) |GROUP_CONCAT(text) |GROUP_CONCAT(text) |
------------------------------------------------------------------------
1_1,1_1,1_1 |1_1 ,1_2 ,1_|1_1,1_2,1_3 |
|3 | |
------------------------------------------------------------------------
2_1,2_2,2_3 |2_1 ,2_1 ,2_|2_1,2_2,2_3 |
|1 | |
------------------------------------------------------------------------
3_1,3_2,3_3 |3_1 ,3_2 ,3_|3_1,3_1,3_1 |
|3 | |
总数目:3
-- 以id分组,把a,b,c字段的值以降序分别在同一行打印出来
SELECT GROUP_CONCAT(a order by a desc),GROUP_CONCAT(b order by b desc),GROUP_CONCAT(c order by c desc) FROM tab1 GROUP BY id ORDER BY id;
GROUP_CONCAT(text) |GROUP_CONCAT(text) |GROUP_CONCAT(text) |
------------------------------------------------------------------------
1_1,1_1,1_1 |1_3 ,1_2 ,1_|1_3,1_2,1_1 |
|1 | |
------------------------------------------------------------------------
2_3,2_2,2_1 |2_1 ,2_1 ,2_|2_3,2_2,2_1 |
|1 | |
------------------------------------------------------------------------
3_3,3_2,3_1 |3_3 ,3_2 ,3_|3_1,3_1,3_1 |
|1 | |
总数目:3
-- 以id分组,把a,b,c字段的值分别在同一行打印出来, a,b,c字段重复的值只打印一遍
SELECT GROUP_CONCAT(DISTINCT a),GROUP_CONCAT(DISTINCT b),GROUP_CONCAT(DISTINCT c) FROM tab1 GROUP BY id ORDER BY id;
GROUP_CONCAT(text) |GROUP_CONCAT(text) |GROUP_CONCAT(text) |
------------------------------------------------------------------------
1_1 |1_1 ,1_2 ,1_|1_1,1_2,1_3 |
|3 | |
------------------------------------------------------------------------
2_1,2_2,2_3 |2_1 |2_1,2_2,2_3 |
------------------------------------------------------------------------
3_1,3_2,3_3 |3_1 ,3_2 ,3_|3_1 |
|3 | |
总数目:3
-- 以id分组,把a字段的值以降序分别在同一行打印出来,a字段重复的值只打印一遍
SELECT GROUP_CONCAT(DISTINCT a order by a desc) FROM tab1 GROUP BY id ORDER BY id;
GROUP_CONCAT(text) |
------------------------
1_1 |
------------------------
2_3,2_2,2_1 |
------------------------
3_3,3_2,3_1 |
总数目:3
-- 以id分组,把a,b,c字段合并的值以降序分别在同一行打印出来,a,b,c字段合并重复的值只打印一遍
SELECT GROUP_CONCAT(DISTINCT a,b,c order by a desc,b desc,c desc) FROM tab1 GROUP BY id ORDER BY id;
GROUP_CONCAT(text) |
------------------------
1_11_3 1_3,1_11_2 |
1_2,1_11_1 |
1_1 |
------------------------
2_32_1 2_3,2_22_1 |
2_2,2_12_1 |
2_1 |
------------------------
3_33_3 3_1,3_23_2 |
3_1,3_13_1 |
3_1 |
总数目:3
-- 以id分组,'%'为分隔符,把a字段的值分别在同一行打印出来, a字段重复的值只打印一遍
SELECT GROUP_CONCAT(DISTINCT (TAB1.A)::TEXT SEPARATOR '%') AS GROUP_CONCAT FROM SYSDBA.TAB1 GROUP BY TAB1.ID ORDER BY TAB1.ID;
GROUP_CONCAT(text) |
------------------------
1_1 |
------------------------
2_1%2_2%2_3 |
------------------------
3_1%3_2%3_3 |
总数目:3
-- 以id分组,'%'为分隔符,系统表模式下调用group_concat把a字段的值分别在同一行打印出来, a字段重复的值只打印一遍
SELECT INFO_SCHEM.GROUP_CONCAT(DISTINCT (TAB1.A)::TEXT SEPARATOR '%') AS GROUP_CONCAT FROM SYSDBA.TAB1 GROUP BY TAB1.ID ORDER BY TAB1.ID;
GROUP_CONCAT(text) |
------------------------
1_1 |
------------------------
2_1%2_2%2_3 |
------------------------
3_1%3_2%3_3 |
总数目:3
-- 以id分组,'%'为分隔符,以标识符形式调用group_concat把a字段的值分别在同一行打印出来, a字段重复的值只打印一遍
SELECT "GROUP_CONCAT"(DISTINCT (TAB1.A)::TEXT SEPARATOR '%') AS GROUP_CONCAT FROM SYSDBA.TAB1 GROUP BY TAB1.ID ORDER BY TAB1.ID;
GROUP_CONCAT(text) |
------------------------
1_1 |
------------------------
2_1%2_2%2_3 |
------------------------
3_1%3_2%3_3 |
总数目:3
-- 删除表
DROP TABLE tab1;