




字符集¶
A接口和W接口区别¶
微软在指定ODBC标准时,对于应用程序与ODBC接口存在数据交互的情况下,定义了一套A接口和W接口, A接口可以处理应用程序任何宽字符以外的其他字符集; 而W接口处理应用程序为宽字符的, ODBC标准只支持UCS-2的宽字符,它使用 16 位整数 (固定长度) 来表示字符。
比如接口SQLPrepareA和SQLPrepareW,这个两个接口是应用程序给odbc驱动给一个SQL语句, 应用程序中这个sql语句字符串的编码可以是GBK、UTF8、以及UTF16,而SQLPrepareA只能处理应用程序编码为单字节的(GBK、UTF8), 而SQLPrepareW可以处理UTF16、UNICODE这类宽字符的编码。
驱动编码转换规则¶
神通数据库的ODBC客户端的字符一般是通过平台来获取的,比如windows默认为GBK,而Linux下默认为UTF8。如果开发者想改变, 则数据源管理器中添加ClientCharset参数来改变(连接字符串中也可以添加这个参数)。这个字符集主要是用于与数据库端的交互, 比如数据库的字符为utf8,odbc客户端的字符集是GBK,则odbc给数据库发送数据时,会将数据从GBK转换为UTF8格式发给数据库; odbc收到数据库端的UTF8数据时也会转换为为GBK格式。
字符集的处理还涉及到应用程序,因为应用程序中的数据编码与ODBC客户端的编码也可能不同,因此odbc驱动也会将应用程序的给odbc驱动的数据有程序的编码转换为odbc客户端的编码。
字符集转换逻辑如下,A接口和W接口有所区别:
- A接口编码转换逻辑如下:
A接口odbc是不会将应用的编码转换为ODBC的编码,如果应用程序的编码和ODBC不一致,会造成乱码问题,因此必须将odbc的编码与应用程序的编码保持一致。
注意
应用程序的编码指的是最终传递给odbc接口的数据编码。
假如我们应用程序的编码为utf8,odbc客户端的编码需要与应用程序保持一致设置为utf8,数据库的编码为gbk,应用程序在调用odbc时,字符集转换流程为:

从举例的逻辑上来说,在odbc层进行了一次转换,一定程度上会影响效率,最好的状态是应用程序字符集、odbc客户度字符集、数据库的字符集三者是保持一致的, 这样就不用进行转换,效率更高。开发者理解转码逻辑后可设置各个层面的编码,以减少编码转换次数。
- w接口编码转换逻辑如下:
W接口应用程序传递宽字符编码的数据给odbc,odbc此时会将宽字符编码转换为ASCII编码,这是固定流程;如果ODBC的客户端编码设置为了UTF8, 则此时ODBC会将ASCII编码数据转换为UTF8编码数据,在将数据发送给数据库时,如果数据库的编码也为UTF8,则不用转换直接发送; 如果数据库的编码为GBK,与ODBC客户端编码不相同,则ODBC会将数据转换为数据库的格式后进行发送。
假如我们应用程序的编码为utf8,odbc客户端的编码需要与应用程序保持一致设置为utf8,数据库的编码为gbk,应用程序在调用odbc时,字符集转换流程为:
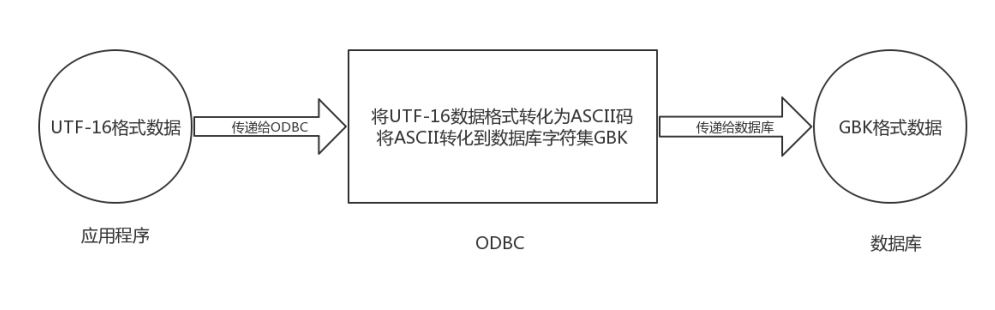
从举例的逻辑上来说,在odbc层进行了两次转换,一定程度上会影响效率,最好的状态是应用程序字符集、odbc客户度字符集、数据库的字符集三者是保持一致的,这样就不用进行转换,效率更高。开发者理解转码逻辑后可设置各个层面的编码,以减少编码转换次数。