




绑定和定义¶
通常来说,绑定bind 是对sql语句中长度参数进行输入的一种方式,是一种输入参数,而定义define是对于查询返回结果集列的一种内存映射,是一种输出参数。
绑定操作¶
绑定是将程序中C变量与SQL语句中占位符进行对应的过程,SQL语句在执行的时候,会将绑定的C变量中,将值和SQL语句一起发送给数据库服务器端进行执行。比如一个Insert语句:
INSERT INTO emp VALUES (:empno, :ename; :job; :sal; :deptno)
声明如下变量:
绑定使得占位符名称和变量地址之间建立映射。绑定同时指明变量的数据类型和长度。如下图所示:
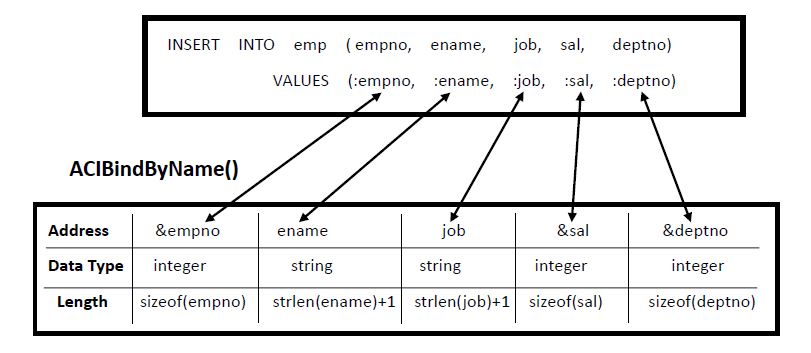
由于绑定是按地址引用进行的,因此如果仅仅更改了绑定变量的值,不必在执行语句的时候重新绑定。
占位符必须以半角的:开始,:后面是占位符的名称
按位置绑定¶
参数按照占位符在SQL语句中的顺序进行绑定。通过 ACIBindByPos 、 ACIBindByPos2 函数的调用来实现输入变量和占位符位置的绑定。位置的顺序是从1开始的,如果位置大于占位符的个数会报错,比如:
INSERT INTO emp VALUES (:empno, :ename; :job; :sal; :deptno)
其中的五个占位符可以通过 ACIBindByPos 函数并传入占位符的位置给函数的位置参数来实现绑定。比如, :empno可以通过调用位置参数为1的 ACIBindByPos 来实现绑定,:ename则传入2,以此类推。
注意:同一个列可以绑定多次,但以最后一次绑定的变量和类型为准;
按名称绑定¶
参数按照SQL语句中的占位符名称来绑定的,绑定的顺序不受限制,通过 ACIBindByName 、 ACIBindByName2 函数的调用来实现输入变量和占位符位置的绑定。
如果绑定的变量名称在占位符中不存在,会报错;多个占位符的名称可以相同,此时通过一个绑定就可以。
SELECT empno FROM emp WHERE sal > :some_value AND comm > :some_value
SQL语句中的两个占位符名称相同,通过 ACIBindByName 、 ACIBindByName2 一次性绑定即可,这两个占位符都会与程序中的相同变量进行映射。
注意:
- 同一个列可以绑定多次,但以最后一次绑定的变量和类型为准;
- 如果SQL语句中有相同名称的占位符,通过位置绑定时,必须为每个占位符单独绑定,这与按位置绑定有所不同。
数组绑定¶
常规绑定只能按单个值进行绑定,有时候需要绑定一个数组,因为这个数组有10个值,想一次性进行绑定,以获得更高效的性能。结构体数组的使用可以简化对多行、多列的操作。在创建相关标量数据项的结构体后,可以将从数据库中取出的数据存放到结构体数组中,也可将结构体数组中的数据插入数据库中。
通过 ACIBindArrayOfStruct 函数在结构体项和数据表列之间建立映射关系以指定数据的获取和存放的位置的方式来实现对多行、多列的操作。
- 数据跳转
有两种方式给一个数组数据,因此在设置数据跳转时给的跳转间距时有所区别:
1) 标准数组
标准数值就是创建一个列的数组,比如:
text emp_names[4][20];
代表是有4个元素,每个元素的跳转间距为20,为绑定所设置的跳转参数值应为20,数组中的每个元素被当成单独的单元。
绑定示例:
insert into testtb values (:1,:2);
int id[4];
char col1[4][16];
/*数组赋值。。。。*/
r = ACIBindByPos(m_pstmt, &m_bnd, m_perr, 1, (void *)&id, sizeof(int), SQLT_INT, (void*)indp4, 0, 0, 0, 0, ACI_DEFAULT);
r = ACIBindArrayOfStruct(m_bnd, m_perr, 4, sizeof(int), 0, 0);
r = ACIBindByPos(m_pstmt, &m_bnd, m_perr, 2, (void *)col1, sizeof(col1[0]), SQLT_STR, (void*)indp4, 0, 0, 0, 0, ACI_DEFAULT);
r = ACIBindArrayOfStruct(m_bnd, m_perr, 16, sizeof(int), 0, 0);
2) 结构体
结构体数组是对单个变量的数组的扩展。在操作单个变量的数组时,跳转参数值为数组元素类型所占的字节数,例如Record结构
typedef struct{
int sID;
char sCol1[16];
} Record;
Record rec[4]
Record结构的长度为20,为绑定所设置的跳转参数值应为20,Rec代表有4个元素的结构体数组,举例如下:
insert into testtb values (:1,:2);
typedef struct{
int sID;
char sCol1[16];
} Record;
Record rec[4]
/*结构体数组赋值。。。。*/
r = ACIBindByPos(m_pstmt, &m_bnd, m_perr, 1, (void *)&rec.SID, sizeof(rec.SID), SQLT_INT, 0, 0, 0, 0, 0, ACI_DEFAULT);
r = ACIBindArrayOfStruct(m_bnd, m_perr, 20, sizeof(int), 0, 0);
r = ACIBindByPos(m_pstmt, &m_bnd, m_perr, 2, (void *)rec.sCol1, sizeof(rec.sCol1), SQLT_STR, 0, 0, 0, 0, 0, ACI_DEFAULT);
r = ACIBindArrayOfStruct(m_bnd, m_perr, 20, sizeof(int), 0, 0);
动态绑定¶
如果对 ACIBindByName 或 ACIBindByName2 或 ACIBindByPos 或 ACIBindByPos2 的调用中的mode参数设置为ACI_DATA_AT_EXEC,则需要应用程序使用回调方法在运行时提供数据,需要对 ACIBindDynamic 进行附加调用 。ACI_DATA_AT_EXEC模式时,绑定可以不给数据内存地址和数据内存长度等信息,即使给了,也会被忽略。
通过对 ACIBindDynamic 的调用将设置回调函数,回调函数中提供的数据或片段。 如果选择了ACI_DATA_AT_EXEC模式,但使用了标准的ACI分片提供数据,则无需调用 ACIBindDynamic 。
分片/分段绑定¶
您可以使用ACI执行分段插入、更新;也可以动态提供数据数组方式进行插入和更新,而不是用一个静态的数据数组来插入数据。可以通过分片插入一个比较大的数据,这样可以降低对客户端的内存需求,提高插入效率。分片的大小有应用程序决定,可以统一大小也可以不统一。
当对非常大的字符串类型(TEXT、XML、JSON、CLOB等)或二进制数据块(BLOB、varbinary等)执行操作时,ACI的分段功能特别有用。
在数据插入过程中,必须了解各个函数的调用顺序才能正确实现分片,比如insert操作,必须先多次调用 ACIStmtExecute 来完成数据的插入,如果插入N片数据, ACIStmtExecute 需要被调用N+1次。
除了以下数据类型可以支持分片,其他类型不建议走分片:
- VARCHAR2
- Json
- Xml
- Text
- Varbinary
- Binary
- CLOB
- BLOB
Out参数绑定¶
对于PL/SQL中的OUT参数的绑定,和普通绑入参数一样绑定,但在执行完成后,out参数列的绑定变量中,会有out参数的返回值。
Returning绑定¶
Returning 语法,可以返回insert或update等语句操作数据行的列数据,对于ACI来说是一个返回型参数,returning语句在ACI中的写入如下:
Insert into student values(:id , :name, :age) returning id into :r_id
往student表中插入的id列,通过returning语法将id返回,并用r_id参数进行绑定,对于这个SQL语句来说,r_id如果通过参数顺序绑定,则绑定的顺序号为4:
Int int_out = 0;
ACIBindByPos(stmt,&bin[0],err,4,&int_out,sizeof(int),SQLT_INT,0,0,0,0,0,ACI_DEFAULT);
通过绑定,如果 ACIStmtExecute 正确执行,则在int_out变量中,有返回的id列的值。
Ref Cursor绑定¶
Ref Cursor是在PL中存在一种游标类型,也可以用sys_refcursor类型进行定义,用于通过PL的out参数返回一个结果集。绑定类型用SQLT_RSET。
示例ref cursor的存储过程:
create or replace procedure p_refcursor(p1 int ,p2 sys_refcursor) as
begin
open p2 for select p1 from dual;
end;
/
绑定方式如下:
ACIStmt* cursorStmt;
char* sSQL = "begin p_refcursor(1, :cur); end;";
ACIStmtPrepare(stmt, err, (CONST OraText *)sSQL, (ub4)strlen(sSQL),
ACI_NTV_SYNTAX, ACI_DEFAULT);
ACIBindByPos(stmt,&pBind, err, 1, &cursorStmt, 0,SQLT_RSET,
0, 0,NULL, 0,0,ACI_DEFAULT);
通过绑定,如果 ACIStmtExecute 正确执行,则在cursorStmt变量中存储了一个结果集;由于返回的是一个ACIStmt类型对象,只要再次对cursorStmt进行 ACIDefineByPos 定义操作,可以返回相关的数据。
空值绑定¶
常规来说,开发者对空值的理解可能存在误区,比如字符串类型:分为空串和空值,空串是长度为0的一个字符串(''),而空值即为NULL;神通数据库默认情况下,字符串类型是区分''和NULL的,比如插入以下两条数据:
Insert into test values(1, '');
Insert into test values(2, NULL);
如果用查询:select * from test where c2 is null;则只能查询第二条数据,想查询'',只能写select * from test where c2 = '';
但神通数据库对Oracle的兼容模式COMPATABLE_DBMS(数据库配置参数,非ACI配置参数)会改变这个规则,将COMPATABLE_DBMS设置为1重启数据库后,以上两条insert数据,到数据库中第二个字段其实插入的都是NULL,用select * from test where c2 is null查询可以查询到2条数据,用select * from test where c2 = ''查询不到数据。
ACI中在代码中插入NULL值,只需要在 ACIBindByPos / ACIBindByPos2 / ACIBindByName / ACIBindByName2 的indp参数,将这个参数的传入值赋值为-1,如果是数组绑定,则给分配的indp数组中的每个元素都赋值为-1,这样数组中的每条数据这个字段的值到数据库中都是NULL;如果indp=-1,则会忽略valuep和value_sz这两个参数
Char * tmp = 'abc';
ub2 indp = -1;
R = ACIBindByPos(stmt, &binds, err, 1, tmp, strlen(tmp)+1, SQLT_STR, &indp, 0, 0, 0, 0, 0);
如果你想插入'', 数据库参数COMPATABLE_DBMS必须为0,绑定时 ACIBindByPos / ACIBindByPos2 / ACIBindByName / ACIBindByName2 正常绑定即可,给定的绑定valuep参数中数据没有即可,比如:
Char * tmp = '';
R = ACIBindByPos(stmt, &binds, err, 1, tmp, strlen(tmp)+1, SQLT_STR, 0, 0, 0, 0, 0, 0);
数据定义¶
查询语句将数据从数据库返回到应用程序中,处理查询时,必须为选择列表中的每个列定义一个输出变量或一组输出变量,用于返回数据。 定义过程其实是创建一个关联:该关联确定返回结果的存储变量位置、类型以及格式。
例如,如果您的程序处理以下语句,则通常将定义两个输出变量:一个用于接收从name列返回的值,另一个用于接收从ssn列返回的值:
SELECT name, ssn FROM employees
WHERE empno = 1
如果仅对从name列中检索值感兴趣,则无需为ssn定义输出变量。 如果要处理的SELECT语句返回的查询行不止一行,则您定义的输出变量可以是数组而不是标量值。
根据应用程序需要,定义步骤可以在执行操作之前或之后执行。如果在执行语句之前知道查询列的数据类型,则可以在执行语句之前进行定义;如果应用程序处理的SQL语句时动态的的,没有明确具体的列(有些列是表达式计算的),这时候,需要在执行语句之后,通过获得描述数据来明确查询的每个列的类型和长度,并用这些信息来定义变量或者数值,再执行定义步骤。
ACIDefineByPos或ACIDefineByPos2调用的dty参数指定输出变量的数据类型。当将数据提取到输出变量中时,如果数据库中类型与定义类型不一致,ACI会执行各种数据转换。例如,数据库中的 Timestamp格式的内部数据可以在输出时自动转换为String数据类型。
注意:您可以再次进行define调用以重新定义输出变量,而不必重复或重新执行SQL语句。
按位置定义¶
对于有结果集返回的查询语句,返回数据需要的数据定义过程只能通过位置方式进行定义;通过 ACIDefineByPos 或 ACIDefineByPos2 调用完成的按位置定义。下面这个例子是通过获得查询语句的描述信息,然后通过获得的描述信息进行变量的的定义和ACI接口的数据定义:
//SELECT department_name FROM departments WHERE department_id = 1
printf("Enter employee dept: ");
scanf("%d", &deptno);
/* 如果ACIStmtExecute() 返回 ACI_NO_DATA, 意味着查询无结果,直接返回 */
if ((status = ACIStmtExecute(svchp, stmthp, errhp, 0, 0, (ACISnapshot *) 0, (ACISnapshot *) 0, ACI_DEFAULT)) && (status != ACI_NO_DATA))
{
checkerr(errhp, status);
return ACI_ERROR;
}
if (status == ACI_NO_DATA) {
printf("The dept you entered does not exist.\n");
return 0;
}
/* 后面两条语句获得查询列的描述信息,比如列长度等*/
checkerr(errhp, ACIParamGet ((void *)stmthp, (ub4) ACI_HTYPE_STMT, errhp, (void **)&parmdp, (ub4) 1));
checkerr(errhp, ACIAttrGet ((void*) parmdp, (ub4) ACI_DTYPE_PARAM,
(void*) &deptlen, (ub4 *) &sizelen, (ub4) ACI_ATTR_DATA_SIZE,
(ACIError *) errhp ));
/* 用返回的长度分配数据内存变量,同时定义数据*/
dept = (text *) malloc((int) deptlen + 1);
if (status = ACIDefineByPos(stmthp, &defnp, errhp,
1, (void *) dept, (sb4) deptlen+1,
SQLT_STR, (void *) 0, (ub2 *) 0,
(ub2 *) 0, ACI_DEFAULT))
{
checkerr(errhp, status);
return ACI_ERROR;
}
数组/批量定义¶
在某些情况下,除了对 ACIDefineByPos 或 ACIDefineByPos2 的调用之外,数据定义步骤还需要其他调用。例如,定义一个数组,通过 ACIDefineArrayOfStruct 进行数组绑定。例如,一个查询需要一次性返回多行,必须为每个查询列调用如下三个接口: ACIDefineByPos 或 ACIDefineByPos2 和 ACIDefineArrayOfStruct 就足够了。
必须调用 ACIDefineArrayOfStruct 才能设置每个附加参数,包括数值结构操作所需的skip参数。
- 跳跃参数
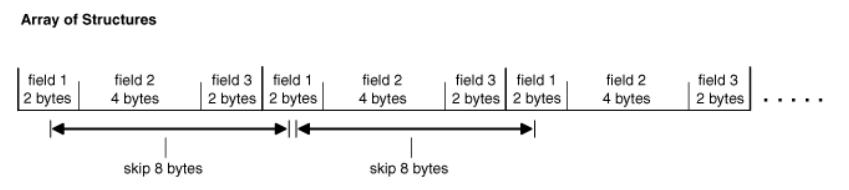
在跨结构数组拆分列数据时,它不再连续存储在数据库中。简单的结构数组存储数据就像是由多个标量数组组成一样。因此必须为要绑定或定义的每个字段指定一个跳跃参数。 此skip参数是在结构数组中再次遇到相同字段之前必须跳过的字节数。通常为一个结构的字节大小。下图展示了参数跳跃的逻辑,在这种情况下,skip参数是字段field1(2个字节),field2(4个字节)和field3(2个字节)的大小之和,即8个字节,总和等于一个结构的大小。
在某些操作系统上,可能有必要将skip参数设置为sizeof(one_array_element)而不是sizeof(struct),因为某些编译器会在结构中插入额外的字节。比如由两个字段ub4和ub1组成的C结构数组:
struct demo {
ub4 field1;
ub1 field2;
};
struct demo demo_array[MAXSIZE];
一些编译器在ub1之后插入3个填充字节,以便正确对齐数组中下一个结构开始的ub4。 在这种情况下,以下语句可能返回不正确的值:
skip_parameter = sizeof(struct demo);
在某些操作系统上,这会产生正确的skip参数8。在其他系统上,此语句将skip_parameter设置为5个字节。 在后一种情况下,请使用以下语句为skip参数获取正确的值:
skip_parameter = sizeof(demo_array[0]);
备注:结构体对齐的问题是需要每个编程人员注意的问题,可以参考 #pragma pack相关使用。
- 结构数组定义
使用结构数组可以简化多行,多列操作的处理。您可以创建一个相关标量数据项的结构,然后从数据库中将值提取到这些结构的数组中,或者从这些结构的数组中将值插入数据库,结构中的成员是需要定义的变量,一个结构的成员可以关联一行,结构数值就代表可以关联多行。
例如,应用程序可能需要从NAME,AGE和SALARY三列中获取多行数据。 该应用程序可以包括一个结构的定义,该结构包含单独的字段来保存数据库表中一行中的NAME,AGE和SALARY数据。 然后,应用程序会将数据提取到这些结构的数组中。
要使用结构数组执行多行,多列操作,请将操作中涉及的每一列与结构中的字段相关联。 此关联是 ACIDefineArrayOfStruct 和 ACIBindArrayOfStruct 调用的一部分,它指定存储数据的位置。
- 标准数组定义
指定单变量数组操作时,相关的跳过等于所考虑的数组的数据类型的大小。 例如,考虑一个声明如下的数组:
text emp_names[4][20];
绑定或定义操作的skip参数为20。然后,将数组中的每个数据元素识别为一个单独的单元,而不是结构的一部分。
- 批量绑定的指示器
结构数组绑定时,可以返回指示器和返回值,您可以声明列级指标变量的数组,并返回与正在获取,插入或更新的信息数组相对应的代码。 这些数组可以具有自己的跳过参数,这些参数在 ACIDefineArrayOfStruct 调用期间指定。
您可以通过多种方式设置程序值和指标变量的结构数组。 考虑一个应用程序,该应用程序从查询中的三个列中提取数据到包含三个字段的结构数组中。 您可以设置三个字段的指标变量结构的对应数组,每个字段都是用于从数据库中获取的一列的列级指标变量。指示符结构中的字段与选择列表项的数量之间没有一对一的关系。
分片/分段定义¶
分段读取之前需要对 ACIDefineByPos 或 ACIDefineByPos2 进行初始调用。如果应用程序使用回调而不是标准轮询机制,则需要附加调用 ACIDefineDynamic 接口。
Lob定义¶
有两种方式可以对lob进行定义:
- 定义一个LOB定位符,而不是实际的LOB值。在这种情况下,通过将LOB定位符传递给ACI的LOB函数来写入或读取LOB值。
- 直接定义一个LOB值,而无需使用LOB定位器。
- 采用LOB定位符方式
可以在单个数据定义调用中定义单个定位器或定位器数组。在每种情况下,应用程序都必须传递LOB定位器的地址,而不是定位器本身的地址。例如,假设应用程序已准备以下SQL语句:
SELECT lob1 FROM some_table;
在此语句中,lob1是LOB列,one_lob是与LOB列对应的定义变量,具有以下声明:
ACILobLocator * one_lob;
然后以下调用将用于绑定占位符并执行该语句:
/* 初始化一个lob指示器 */
ACIDescriptorAlloc(...&one_lob, ACI_DTYPE_LOB...);
...
/* 将指示器的地址进行定义 */
ACIDefineByPos(...,(void *) &one_lob,... SQLT_CLOB, ...);
ACIStmtExecute(...,1,...); /* 1 是迭代次数 */
注意:必须先使用 ACIDescriptorAlloc 函数分配描述符,然后才能使用它们。 在定位器数组中,必须使用 ACIDescriptorAlloc 初始化每个数组元素。 分配BLOB,CLOB和NCLOB时,请使用ACI_DTYPE_LOB作为类型参数。 分配BFILE时使用ACI_DTYPE_FILE。
- 采用LOB数据方式
数据库允许对任何大小LOB的SELECT进行非零定义。 因此,您可以使用 ACIDefineByPos 和PL / SQL定义从LOB列中选择最大允许的数据大小。 因为一行中可以有多个LOB,所以您可以在同一SELECT语句中从每个LOB中选择最大数据大小。比如表定义:
CREATE TABLE lob_tab (C1 CLOB, C2 CLOB);
将SQLT_LNG类型将一个buf中的数据写入到数据库的lob字段中:
/* 一个ACI函数*/
void select_define_before_execute()
{
ub1 buffer1[8000];
ub1 buffer2[8000];
text *select_sql = (text *)"SELECT c1, c2 FROM lob_tab";
ACIStmtPrepare(stmthp, errhp, select_sql, (ub4)strlen((char*)select_sql),(ub4) ACI_NTV_SYNTAX, (ub4) ACI_DEFAULT);
ACIDefineByPos(stmthp, &defhp[0], errhp, 1, (void *)buffer1, 8000,
SQLT_LNG, (void *)0, (ub2 *)0, (ub2 *)0, (ub4) ACI_DEFAULT);
ACIDefineByPos(stmthp, &defhp[1], errhp, 2, (void *)buffer2, 8000,
SQLT_LNG, (void *)0, (ub2 *)0, (ub2 *)0, (ub4) ACI_DEFAULT);
ACIStmtExecute(svchp, stmthp, errhp, 1, 0, (ACISnapshot *)0,
(ACISnapshot *)0, ACI_DEFAULT);
}
备注:可以用SQLT_CHR、SQLT_STR等类型获取数据库的lob数据,但普通方式的lob数据读取长度受 ACIDefineByPos 或 ACIDefineByPos2 函数的 value_sz参数类型限制,比如 ACIDefineByPos 函数的value_sz是一个sb4类型,最大表示的正数为:2147483648字节,约2GB,如果大对象数据超过2GB,返回数据将被截断。
同时,通过普通类型来操作比较大的lob数据性能会比较差,因为他是一次性获取所有数据后才返回,对内存的开销较大,耗时比较长。因此建议只在小对象场景下使用。
PL/SQL输出参数定义¶
不要试图去用数据定义操作define在PL/SQL的out参数值,out参数值只能用ACI绑定操作bind调用返回PL/SQL的返回参数。
空值定义¶
如果数据库中查询的数据是NULL则会通过 ACIDefineByPos / ACIDefineByPos2 接口的indp参数返回-1,因此需要开发者执行后 ACIStmtFetch ,去查看indp参数是否为-1,如果是,则表示数据为NULL,不要再近些定义数据块的处理,否则或导致异常情况。
如果是返回的是空串'',则indp不等于-1,但 ACIDefineByPos 的rlenp参数返回真实获取到的数据长度为0.则代表是空串''。
分片/分段操作¶
ACI执行插入,更新和数据提取都可以采用分段/分片。还可以使用ACI在数组插入或更新的情况下动态提供数据,而不是提供绑定值的静态数组。 您可以按一系列较小的内存完成插入或检索很大的列,从而最大程度地减少了客户端的内存需求。
单个块(内存)的大小由应用程序在运行时确定,并且可以统一或不统一。在对非常大的字符串或二进制数据执行操作(涉及CLOB,BLOB,BINARY,VARBINARY或JSON数据的数据库列的操作)时,ACI的分段功能特别有用。
当最后的 ACIStmtFetch2 调用返回ACI_SUCCESS的值时,分段提取即告完成。
在数据插入过程中,必须了解各个函数的调用顺序才能正确实现分片,比如insert操作,必须先多次调用 ACIStmtExecute 来完成数据的插入,如果插入N片数据, ACIStmtExecute 需要被调用N+1次。
同样,在执行分段提取时,您必须调用 ACIStmtFetch2 超过要提取的块数一次。
支持分片的类型¶
除了以下数据类型可以支持分片,其他类型不建议走分片:
- VARCHAR2
- Json
- Xml
- Text
- Varbinary
- Binary
- CLOB
- BLOB
对所有数据类型使用此功能的另一种方法是为数组插入或更新动态提供数据(详细参阅动态操作章节)。 对于不支持分段操作的数据类型,回调应始终为回调的piecep参数指定ACI_ONE_PIECE。
分段操作方式¶
您可以通过两种方式执行分段操作:
- 使用ACI库中提供的调用在轮询下执行分段操作。
- 使用用户定义的回调函数来提供必要的信息和数据块。
当您将 ACIBindByPos 或 ACIBindByPos2 或 ACIBindByName 或 ACIBindByName2 的模式参数设置为对ACI_DATA_AT_EXEC的调用时,表示ACI应用程序正在运行时动态为INSERT或UPDATE操作提供数据。
同样,当您将 ACIDefineByPos 或 ACIDefineByPos2 调用的模式参数设置为ACI_DYNAMIC_FETCH时,它指示应用程序在提取时动态提供了分配空间来接收数据。
在每种情况下,都可以通过以下两种方式之一提供INSERT,UPDATE或FETCH操作的运行时信息:通过回调函数或使用分段操作。 如果需要回调,则必须进行附加的 ACIBindDynamic 或 ACIDefineDynamic 调用才能注册回调。
数据更新时分片¶
当您在对 ACIBindByPos 或 ACIBindByPos2 或 ACIBindByName 或 ACIBindByName2 的调用中指定ACI_DATA_AT_EXEC模式时,value_sz参数定义了可在运行时提供的数据总大小。
应用程序须准备好根据需要向ACI提供运行时数据缓冲区,并根据分片次数变更缓冲取数据,以完成操作所需的次数。 当不再需要分配的缓冲区时,客户端必须释放它们。
通过以下两种方式之一提供运行时数据:
- 可以使用
ACIBindDynamic函数定义一个回调,该函数在运行时被调用时将返回一部分数据或全部数据。
- 如果未定义回调,则对
ACIStmtExecute的调用将返回ACI_NEED_DATA错误代码。 然后,客户端应用程序使用ACIStmtSetPieceInfo调用提供输入/输出数据缓冲区或片段,该调用指定正在使用的绑定和片段内存。
初始化ACI环境并建立数据库连接和会话后,分段插入将从调用开始,以准备SQL或PL / SQL语句并绑定输入值。
使用标准ACI调用而不是用户定义的回调进行的分段操作不需要调用 ACIBindDynamic 。
在语句准备和绑定之后,应用程序执行 ACIStmtExecute , ACIStmtGetPieceInfo 和 ACIStmtSetPieceInfo 的一系列调用以完成分段操作。 每次调用 ACIStmtExecute 都会返回一个值,该值确定下一步应执行的操作。 通常,应用程序检索一个值,该值指示必须插入下一个片段,并用该片段填充缓冲区,然后执行插入,插入最后一块后,操作完成。
请记住,插入缓冲区可以是任意大小,并在运行时提供。 另外每个插入的数据分片大小不一定相同,因为每个 ACIStmtSetPieceInfo 调用都会确定要插入的每个片段的大小。
备注:如果所有插入都使用相同的片段大小,并且插入的数据大小不能被片段大小整除,则最后插入的片段大小会小于内存块大小。 您必须在最后的 ACIStmtSetPieceInfo 调用中指出最后一个片段数据的长度,以解决此问题。
分片/分段的执行流程如下:
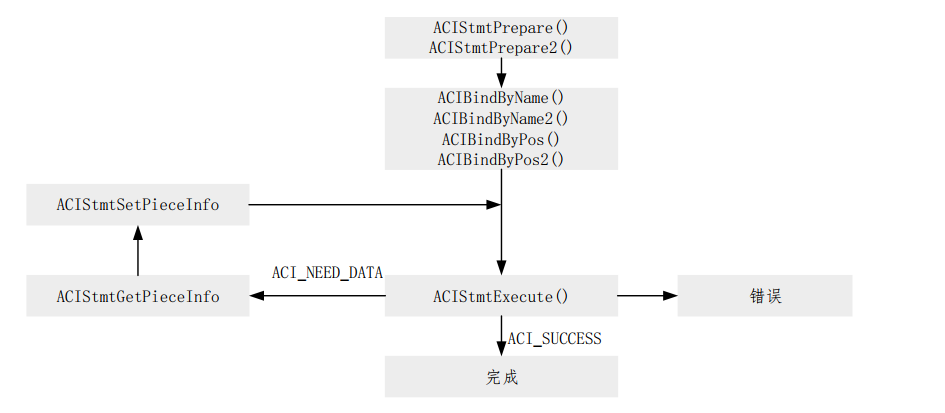
- 通过使用
ACIStmtPrepare2初始化ACI环境,分配必要的句柄,连接到服务器,授权用户并准备语句请求。 - 通过使用
ACIBindByName或ACIBindByName2或ACIBindByPos或ACIBindByPos2来绑定占位符。 您无需指定所使用的块的实际大小(指定了也会被忽略),但是必须指定value_sz参数提供可以在运行时提供的数据的总大小。 - 第一次调用
ACIStmtExecute时未插入任何数据,并且返回ACI_NEED_DATA错误代码。 如果返回任何其他值,则表明发生了错误。 - 调用
ACIStmtGetPieceInfo返回有关必须插入的片段的信息。ACIStmtGetPieceInfo的参数包括一个指向值的指针,该值指示所需的片段是第一片段ACI_FIRST_PIECE还是后续片段ACI_NEXT_PIECE。 - 应用程序使用要插入的数据填充缓冲区,并使用这些参数调用
ACIStmtSetPieceInfo
- 指向一块数据内存的指针
- 指向一块数据内存数据长度的变量指针
- 指示这是第一块(ACI_FIRST_PIECE),中间块(ACI_NEXT_PIECE)还是最后一块(ACI_LAST_PIECE)的值
- 再次调用
ACIStmtExecute。 如果在步骤5中指示了ACI_LAST_PIECE,并且ACIStmtExecute返回ACI_SUCCESS,则所有片段均已成功插入。 如果ACIStmtExecute返回ACI_NEED_DATA,请返回到步骤3进行下一次插入。 如果ACIStmtExecute返回任何其他值,则发生错误。
成功插入最后一块后,分段操作即告完成。 这由最终的 ACIStmtExecute 调用的ACI_SUCCESS返回值指示。
更新时的分段/分片操作用类似方式执行。在分段更新操作中,将使用要更新的数据填充插入缓冲区,并调用 ACIStmtExecute 来执行更新。
分段insert的一个示例,通过分片往clob中写入一个15个字节长度的数据,第一片插入10字节、第二片插入4字节,第三片插入1字节:
// create table ociTest(id int, val1 clob)
char *isql = "insert into ociTest(id, val1) values(1, empty_clob())";
ub4 getype = 0;
ub1 in_out = 0;
ub4 iter = 0;
ub4 idx = 0;
ub1 piece = 0;
void *hndl = NULL;
char buf[15]="f123456789";
ub4 alne = 10;
sb2 ind = 0;
//准备插入语句
ACIStmtPrepare(stmt, err, (CONST OraText*)isql, (ub4)strlen(isql), ACI_NTV_SYNTAX,ACI_DEFAULT);
ACIStmtExecute(svc,stmt,err,1,0,NULL,NULL,ACI_DEFAULT);
//插入数据
ACI_SUCCESS,ACIStmtPrepare(stmt, err, (CONST OraText*)usql, (ub4)strlen(usql), ACI_NTV_SYNTAX,ACI_DEFAULT);
ACIBindByName(stmt, &hBind[0], err, (OraText*)":blob",(sb4)strlen(":blob"), 0, 15, SQLT_STR,0,0,0,0,0,ACI_DATA_AT_EXEC); //指定模式为ACI_DATA_AT_EXEC
//没有插入任何数据
ACIStmtExecute(svc,stmt,err,1,0,NULL,NULL,ACI_DEFAULT);
/* 获得分片信息,第一次执行,piece为ACI_FIRST_PIECE */
ACIStmtGetPieceInfo(stmt, err, (void**)(&hndl), &getype, &in_out, &iter, &idx, &piece);
/* 设置分片信息, piece为ACI_FIRST_PIECE,alne为10 */
ACIStmtSetPieceInfo(hndl, getype, err, buf, &alne, piece, &ind, &rcode);
/* 插入第一个分片,执行后r为ACI_NEED_DATA,执行后alne的返回值也应该为10 */
r = ACIStmtExecute(svc,stmt,err,1,0,NULL,NULL,ACI_DEFAULT);
/* 第二片, piece 为 ACI_NEXT_PIECE */
ACIStmtGetPieceInfo(stmt, err, (void**)(&hndl), &getype, &in_out, &iter, &idx, &piece);
alne = 4;
/* 第二片只插入4个字节 */
ACIStmtSetPieceInfo(hndl, getype, err, buf, &alne, piece, &ind, &rcode);
/* 插入第二个分片,执行后r为ACI_NEED_DATA,执行后alne的返回值也应该为4 */
R = ACIStmtExecute(svc,stmt,err,1,0,NULL,NULL,ACI_DEFAULT);
/* 第三片, piece 为ACI_LAST_PIECE */
ACIStmtGetPieceInfo(stmt, err, (void**)(&hndl), &getype, &in_out, &iter, &idx, &piece);
piece = ACI_LAST_PIECE;
alne = 1;
ACIStmtSetPieceInfo(hndl, getype, err, buf1, &alne, piece, &ind, &rcode);
/* 插入第三个分片,执行后r为ACI_SUCCESS,执行后alne的返回值也应该为1 */
r = ACIStmtExecute(svc,stmt,err,1,0,NULL,NULL,ACI_DEFAULT);
数据查询时分片¶
调用 ACIDefineByPos 或 ACIDefineByPos2 时,将mode参数设置为ACI_DYNAMIC_FETCH的情况下,应用程序可以在获取时指定有关数据缓冲区的信息。
您可能还需要调用 ACIDefineDynamic 来设置一个回调函数,该回调函数被调用以获取有关您的数据缓冲区的信息。
通过以下两种方式之一提供运行时数据:
- 您可以使用
ACIDefineDynamic函数定义一个回调。 value_sz参数定义运行时提供的数据的最大大小。 当客户端库需要缓冲区以返回获取的数据时,将调用回调以提供运行时缓冲区,在该缓冲区中可以返回一部分数据或全部数据。 - 如果未定义回调,则返回ACI_NEED_DATA错误代码,然后客户端应用程序可以使用
ACIStmtSetPieceInfo提供OUT数据缓冲区或片段。ACIStmtGetPieceInfo调用提供有关涉及哪些定义和涉及哪些部分的信息。
提取缓冲区可以具有任意大小。 另外,每个获取的块不必具有相同的大小。唯一的要求是,最终访存的大小必须恰好是剩余的最后一块的大小。 每个 ACIStmtSetPieceInfo 调用都会确定要获取的每个片段的大小。
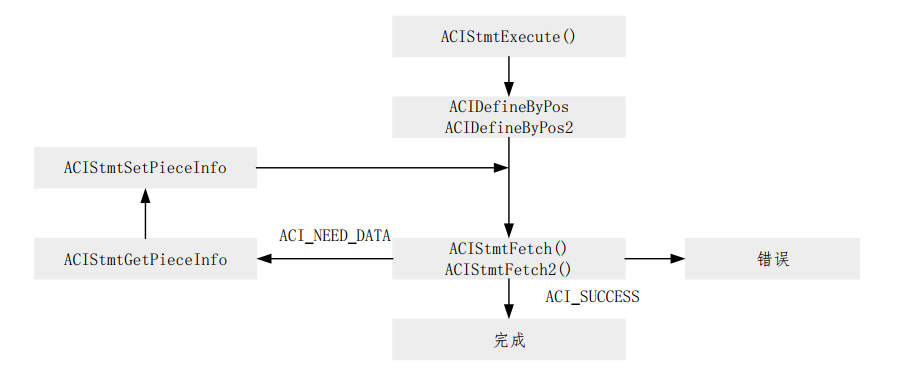
- 使用
ACIStmtExecute初始化ACI环境,分配必要的句柄,连接到数据库,授权用户,准备语句并执行该语句。 - 通过使用
ACIDefineByPos或ACIDefineByPos2将模式设置为ACI_DYNAMIC_FETCH来定义输出变量。此时,您无需指定定义内存块的实际大小,但必须提供要在运行时获取的数据的总大小value_sz。 - 第一次调用
ACIStmtFetch2/ACIStmtFetch。没有检索到任何数据,并且返回ACI_NEED_DATA错误代码。如果返回任何其他值,则发生错误。 - 调用
ACIStmtGetPieceInfo以获取有关要获取的分段的信息。 piecep参数指示是第一块(ACI_FIRST_PIECE),后续块(ACI_NEXT_PIECE)还是最后一块(ACI_LAST_PIECE)。 - 调用
ACIStmtSetPieceInfo以指定获取缓冲区。 - 再次调用
ACIStmtFetch2/ACIStmtFetch以检索实际片段。如果ACIStmtFetch2返回ACI_SUCCESS,则所有片段均已成功获取。如果ACIStmtFetch2返回ACI_NEED_DATA,则返回到步骤(4)处理下一块。如果返回任何其他值,则发生错误。
分段select的一个示例,通过分片往clob中写入一个15个字节长度的数据,第一片插入10字节、第二片插入4字节,第三片插入1字节:
/* 表定义和数据
create table ociTest(c1 varchar(50));
insert into ociTest values('123456789abcdef');
*/
ACIDefine *hDef[2];
char *ssql = "select * from ociTest";
char *estr = "123456789abcdef";
ub4 getype = 0;
ub1 in_out = 0;
ub4 iter = 0;
ub4 idx = 0;
ub1 piece = 0;
void *hndl = NULL;
char buf[15]={0};
ub4 alne = 3;
sb2 ind = 0;
ub2 rcode = 0;
ub4 i = 0;
sb4 offset = 1;
int deflen = 5;
ACISessionBegin (svc, err, ses, ACI_CRED_RDBMS, ACI_DEFAULT);
… …
//查询数据
ACIStmtPrepare(stmt, err, (CONST OraText*)ssql, (ub4)strlen(ssql), ACI_NTV_SYNTAX,ACI_DEFAULT);
ACIDefineByPos(stmt,&hDef[0],err,1,NULL,deflen,SQLT_STR,NULL,NULL,NULL,ACI_DYNAMIC_FETCH);
ACIStmtExecute(svc,stmt,err, 0, 0, NULL, NULL,ACI_DEFAULT);
r = ACIStmtFetch2(stmt, err, 1, ACI_FETCH_NEXT, offset, ACI_DEFAULT);
//r = ACI_NEED_DATA
//获取并设置分段信息
//第一片
ACIStmtGetPieceInfo (stmt, err, (void**)(&hndl), &getype, &in_out, &iter, &idx, &piece);
// getype = ACI_HTYPE_DEFINE , in_out = ACI_PARAM_OUT, iter = 0
// piece = ACI_FIRST_PIECE,alne = 3
ACIStmtSetPieceInfo(hndl, getype, err, buf, &alne, piece, &ind, &rcode);
ACIStmtFetch2(stmt, err, 1, ACI_FETCH_NEXT, offset, ACI_DEFAULT);
//r = ACI_NEED_DATA, buf变量的数据为123
//第二片
offset += alne;
alne = 4;
memset(buf, 0, sizeof(buf));
ACIStmtGetPieceInfo(stmt, err, (void**)(&hndl), &getype, &in_out, &iter, &idx, &piece);
// getype = ACI_HTYPE_DEFINE , in_out = ACI_PARAM_OUT, iter = 0
// piece = ACI_NEXT_PIECE,alne = 4
ACIStmtSetPieceInfo(hndl, getype, err, buf, &alne, piece, &ind, &rcode);
ACIStmtFetch2(stmt, err, 1, ACI_FETCH_NEXT, offset, ACI_DEFAULT);
//r = ACI_NEED_DATA, buf变量的数据为4567
//第三片
offset += alne;
alne = 8;
memset(buf, 0, sizeof(buf));
ACIStmtGetPieceInfo(stmt, err, (void**)(&hndl), &getype, &in_out, &iter, &idx, &piece);
// getype = ACI_HTYPE_DEFINE , in_out = ACI_PARAM_OUT, iter = 0
// piece = ACI_NEXT_PIECE,alne = 8
piece = ACI_LAST_PIECE
ACIStmtSetPieceInfo(hndl, getype, err, buf, &alne, piece, &ind, &rcode);
ACIStmtFetch2(stmt, err, 1, ACI_FETCH_NEXT, offset, ACI_DEFAULT);
//r = ACI_NEED_DATA, buf变量的数据为89abcdef
ACISessionEnd(svc,err,ses,ACI_DEFAULT));
大对象分片读取¶
有两种方式可以对大对象lob在定义和绑定操作时进行分片:
- 用普通数据接口
您可以使用SQLT_CHR(VARCHAR2)或SQLT_LNG(LONG)作为以下函数的输入数据类型,为CLOB列绑定或定义字符数据。 您还可以为BLOB列绑定或定义原始数据使用SQLT_LBI和SQLT_BIN作为以下函数的输入数据类型:
同样,CLOB和BLOB列支持后面介绍的所有分段操作。
- 用lob描述符
使用SQLT_CLOB(CLOB)或SQLT_BLOB(BLOB)作为以下函数的输入数据类型,为CLOB和BLOB列绑定或定义LOB定位器:
您必须调用ACILob* 函数来读取和处理数据。 ACILobRead2 和 ACILobWrite2 支持分段和回调模式。
类型的交叉绑定/定义¶
对于bind和define,应用程序绑定/定义的类型可以与数据库中的类型不相同,但必须能实现互转,这个转换的过程是有驱动隐式进行或者数据库服务端隐式进行。
比如bind绑定insert的插入参数,数据类型为int,应用程序可以用SQLT_CHR、SQLT_STR、SQLT_INT等类型进行绑定,绑定的内存中的数据必须和给定的类型一致,且绑定类型能转换到数据库中的类型,部分数据可以转换,但可能会丢失数据,比如应用程序绑定一个1.1的浮点数,数据库是int,到数据库中会变为1,丢失了小数位。
对于define定义,同样如果数据库中的类型是int,应用程序可以用SQLT_CHR、SQLT_STR、SQLT_INT多种类型来进行数据获取,ACI接口会实现这个数据的转换,转换不成功会进行报错处理。