




ACI编程基础¶
编程步骤¶
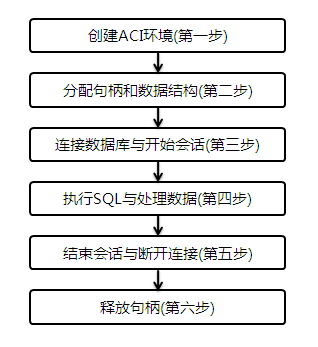
ACI用户编程的基本流程如下:
- 初始化神通ACI接口的运行环境
- 分配环境句柄、语句句柄、服务器句柄、会话句柄等数据结构
- 建立与神通数据库的连接以及创建用户会话
- 通过SQL语句与神通数据库服务器交互,然后对获取的数据进行处理
- 结束用户会话,断开ACI接口与神通数据库的连接
- 释放在程序中所分配的各类句柄和资源
对于第四步进行分解:一个SQL语句在ACI应用程序中的执行步骤一般如下:
- 准备SQL语句
调用函数 ACIStmtPrepare
- 在SQL语句中绑定需要输入到SQL语句中的变量
对于DML语句来说,由于它带有输入变量,我们可以通过调用一个或者多个函数 ACIBindByPos / ACIBindByPos2 / ACIBindByName / ACIBindByName2 等把输入变量的地址绑定在DML语句中的占位符中;
- 执行SQL语句
调用 ACIStmtExecute 函数。对于DDL语句到这一步就完成了一个语句的执行
- 描述SQL中的输出的数据
如果有必要的话,我们可以调用函数 ACIParamGet 与 ACIAttrGet 来获取我们所读取的记录的字段个数、字段的数据类型以及字段数据定义的最大长度。
- 定义输出变量
对于DQL(Data Query Language)语句,即SELECT的查询语句,需要定义一定数量的变量用来接受所选择列的数据。我们可以调用 ACIDefineByPos 函数等来完成这个任务。也就建立SQL语句所返回的数据与应用程序中变量的关系。
- 获取数据
我们可以调用函数 ACIStmtFetch 来把用SELECT选中的记录的数据赋予应用程序中的变量。过程以及过程中调用到的函数如所示。
线程安全¶
要利用线程安全性,应用程序必须在线程安全的操作系统上运行。应用程序通过使用ACI_THREADED作为mode参数的值进行 ACIEnvCreate 或 ACIEnvNlsCreate 调用来指定它在多线程环境中运行。所有后续对 ACIEnvCreate 的调用也必须使用ACI_THREADED进行。
如果应用程序是单线程的,则无论操作系统是否是线程安全的,应用程序都必须将ACI_DEFAULT的值传递给 ACIEnvCreate 或 ACIEnvNlsCreate 。 在ACI_THREADED模式下运行的单线程应用程序可能会导致性能降低。
备注1:ACI调用的大多数处理都在服务器上进行,因此如果使用ACI调用的两个线程进入同一连接,则其中一个线程可以被阻塞,而另一个线程在服务器上完成处理;
备注2:为应用程序中的每个线程使用一个错误句柄,因为ACI错误可能会被其他线程覆盖;
备注3:不指定线程安全模式,在多线程中共用一个链接可能会导致操作返回异常,严重情况可能会数据库服务异常。
全球字符集¶
ACI支持程序数据字符集到数据库字符集之间的自动转换,通过设置配置文件中的enable_encoding参数或者通过 ACIAttrSet 接口设置是否进行转码,默认会开启转换。转换规则:将客户端的字符集转换为数据库字符集,客户端字符集的为当前操作系统的字符集;数据库字符集在数据库创建时指定,如果不指定,默认为:windows下数据库字符集为GBK,Linux下字符集为UTF8。
当为客户端字符集都指定ACI_UTF16ID时,所有元数据以及绑定和定义的数据都以UTF-16编码。 元数据包括SQL语句、用户名、错误消息和列名等。所有元文本数据参数(text * )被假定为UTF-16编码的Unicode文本数据类型(utext * )。
要使用ACI_UTF16ID字符集ID初始化的ACIEnv()函数准备SQL语句时,请使用(utext * )字符串调用 ACIStmtPrepare / ACIStmtPrepare2 函数。 以下示例仅在Windows平台上运行,可能需要更改其他平台的wchar_t数据类型:
const wchar_t sqlstr[] = L"SELECT * FROM ENAME=:ename";
...
ACIStmt* stmthp;
sts = ACIHandleAlloc(envh, (void **)&stmthp, ACI_HTYPE_STMT, 0, NULL);
status = ACIStmtPrepare(stmthp, errhp,(const text*)sqlstr,
wcslen(sqlstr), ACI_NTV_SYNTAX, ACI_DEFAULT);
要绑定和定义数据,不必设置ACI_ATTR_CHARSET_ID属性,因为ACIEnv()函数已经使用UTF-16字符集ID进行了初始化。 绑定变量名称也必须是UTF-16字符串。
ACIBindByName(stmthp1, &bnd1p, errhp, (const text*)L":ename",
(sb4)wcslen(L":ename"), (void *) ename, sizeof(ename), SQLT_STR, (void
*)&insname_ind, (ub2 *) 0, (ub2 *) 0, (ub4) 0, (ub4 *)0,ACI_DEFAULT);
ACIAttrSet((void *) bnd1p, (ub4) ACI_HTYPE_BIND, (void *)
&ename_col_len, (ub4) 0, (ub4)ACI_ATTR_MAXDATA_SIZE, errhp);
...
/* Unicode 数据 */
ACIDefineByPos (stmthp2, &dfn1p, errhp, (ub4)1, (void *)ename, (sb4)sizeof(ename), SQLT_STR, (void *)0, (ub2 *)0,(ub2*)0, (ub4)ACI_DEFAULT);
客户端字符集设置¶
函数 ACIEnvNlsCreate 在应用程序中设置字符集信息。 一个应用程序可以使用不同的客户端字符集ID在同一系统环境中初始化多个环境句柄。 例如:
ACIEnvNlsCreate(ACIEnv **envhpp, ..., csid, ncsid);
在此示例中,csid是字符集ID的值,而ncsid是国家字符集ID的值(不支持)。 可以是0或ACI_UTF16ID。 如果两者均为0,则等效于使用 ACIEnvCreate 。 其他参数与 ACIEnvCreate 调用相同。
ACIEnvNlsCreate函数是对字符集进行编程控制的增强功能,因为它可以使用ACI_UTF16ID。
通过函数 ACIEnvNlsCreate 设置字符集ID时,它们将替换NLS_OSCAR_LANG环境变量中的设置。 可以通过 ACIEnvNlsCreate 函数指定除AL16UTF16之外的任何数据库字符集ID,以指定元数据,字符串数据的编码。
ACI支持的字符集id和字符集名称对应关系:
| 编号 | 字符集ID(charset可传入值) | ACI宏 | 字符集名称(NLS_OSCAR_LANG可设置) |
|---|---|---|---|
| 1 | 1 | —— | US7ASCII |
| 2 | 852 | —— | ZHS16GBK |
| 3 | 854 | —— | ZHS32GB18030 |
| 4 | 865 | —— | ZHT16BIG5 |
| 5 | 871 | —— | UTF8 |
| 6 | 873 | —— | AL32UTF8 |
| 7 | 1000 | ACI_UTF16ID、ACI_UCS2ID | UTF16 |
可以通过 ACINlsEnvironmentVariableGet 函数来获取NLS_OSCAR_LANG环境变量中的字符集。
如果 ACIEnvNlsCreate 的charset参是为0且没有设置NLS_OSCAR_LANG环境变量,则ACI会默认以客户端操作系统的字符集作为ACI的客户端字符集,Windows一般为GBK,Linux一般为UTF8。
ACIEnvNlsCreate接口字符集优先顺序:
ACIEnvNlsCreate中设置了charset且是非零
- 获取NLS_OSCAR_LANG环境变量指定的字符集
- 若干NLS_OSCAR_LANG没有,则获得系统字符集(系统环境变量:LANG)
- 若操作系统字符集获取不到,则采用默认值:windows:GBK,Linux:UTF8
ACIEnvCreate接口字符集优先顺序:
- 获取NLS_OSCAR_LANG环境变量指定的字符集
- 若干NLS_OSCAR_LANG没有,则获得系统字符集(系统环境变量:LANG)
- 若操作系统字符集获取不到,则采用默认值:windows:GBK,Linux:UTF8
ACI字符集控制接口¶
如果已在 ACIEnvNlsCreate 中使用此值,则 ACINlsGetInfo 函数将返回有关ACI_UTF16ID的信息。
ACIAttrGet函数返回传递给ACIEnvNlsCreate的字符集ID。 这用于获取ACI_ATTR_ENV_CHARSET_ID。 返回的包括值ACI_UTF16ID。
如果 ACIEnvNlsCreate 将charset参数设置为NULL,则返回NLS_OSCAR_LANG环境变量中的字符集ID。
通过ACIAttrSet函数重置ACI_ATTR_CHARSET_FORM属性,该函数会将字符ID设置为默认值。 ACIEnvNlsCreate 设置charset字符集的合格字符集ID包括ACI_UTF16ID等。
ACIBindByName和ACIBindByPos函数将变量与ACIEnvNlsCreate调用中的默认字符集绑定在一起,包括ACI_UTF16ID。 如果使用ACIEnvNlsCreate,则实际长度和返回的长度始终以字节为单位。
ACIDefineByPos函数使用ACIEnvNlsCreate中的charset值(默认值为ACI_UTF16ID)定义变量。 如果使用ACIEnvNlsCreate,则实际长度和返回的长度始终以字节为单位。 绑定和定义句柄的行为不同于使用ACIEnvCreate且字符集设置为ACI_UTF16ID的绑定和定义句柄的字符集ID的行为。
ACI字符集转换¶
如果客户端字符集和服务器字符集不同,则会在ACI客户端和数据库服务器之间进行字符集转换。 根据情况,转换发生在客户端上。
如果您不恰当地调用ACI API,则在转换过程中可能会丢失数据。 如果服务器和客户端字符集不同,那么当目标字符集小于源字符集时,您可能会丢失数据。 如果两个字符集都是Unicode字符集(例如,UTF8和AL16UTF16),则可以避免此潜在问题。
数据转换可能导致数据扩展,这可能导致缓冲区溢出。 对于绑定操作,必须将ACI_ATTR_MAXDATA_SIZE属性设置为足够大的大小,以将扩展的数据保存在服务器上。为了定义操作,客户端应用程序必须为扩展的数据分配足够的缓冲区空间。 缓冲区的大小应为扩展数据的最大长度。 您可以通过以下计算来估计最大缓冲区长度:
- 获取列数据字节大小。
- 将其乘以客户端字符集中每个字符的最大字节数。
此方法是最简单,最快的方法,但它可能不准确并且会浪费内存。 它适用于任何字符集组合。 例如,对于UTF-16数据绑定和定义,以下示例计算客户端缓冲区:
ub2 csid = ACI_UTF16ID;
oratext *selstmt = "SELECT ename FROM emp";
counter = 1;
...
ACIStmtPrepare(stmthp, errhp, selstmt, (ub4)strlen((char*)selstmt),
ACI_NTV_SYNTAX, ACI_DEFAULT);
ACIStmtExecute ( svchp, stmthp, errhp, (ub4)0, (ub4)0,
(CONST ACISnapshot*)0, (ACISnapshot*)0,
ACI_DESCRIBE_ONLY);
ACIParamGet(stmthp, ACI_HTYPE_STMT, errhp, &myparam, (ub4)counter);
ACIAttrGet((void*)myparam, (ub4)ACI_DTYPE_PARAM, (void*)&col_width,
(ub4*)0, (ub4)ACI_ATTR_DATA_SIZE, errhp);
...
maxenamelen = (col_width + 1) * sizeof(utext);
cbuf = (utext*)malloc(maxenamelen);
...
ACIDefineByPos(stmthp, &dfnp, errhp, (ub4)1, (void *)cbuf,
(sb4)maxenamelen, SQLT_STR, (void *)0, (ub2 *)0,
(ub2*)0, (ub4)ACI_DEFAULT);
ACIAttrSet((void *) dfnp, (ub4) ACI_HTYPE_DEFINE, (void *) &csid,
(ub4) 0, (ub4)ACI_ATTR_CHARSET_ID, errhp);
ACIStmtFetch(stmthp, errhp, 1, ACI_FETCH_NEXT, ACI_DEFAULT);
...
支持在数据库字符集和utf16(16位,固定宽度Unicode编码)之间进行转换。 如果字符没有从utf16到数据库字符集的映射,则使用替换字符。 因此,在没有数据丢失的情况下,并非总是可能转换回原始字符数据。
涉及utf16字符集的字符集转换功能需要数据绑定并定义要在ub2地址处对齐的缓冲区,否则会引发错误。
示例如下:
size_t MyConvertMultiByteToUnicode(envhp, errhp, dstBuf, dstSize, srcStr)
ACIEnv *envhp;
ACIError *errhp;
ub2 *dstBuf;
size_t dstSize;
OraText *srcStr;
{
size_t dstLen = 0;
size_t srcLen = 0;
OraText tb[ACI_NLS_MAXBUFSZ]; /* 字符集名 */
ub2 cid; /* 字符集id */
/* 获得本地字符集 */
checkerr(errhp, ACINlsGetInfo(envhp, errhp, tb, sizeof(tb),
ACI_NLS_CHARACTER_SET));
cid = ACINlsCharSetNameToId(envhp, tb);
if (cid == ACI_UTF16ID)
{
ub2 *srcStrUb2 = (ub2*)srcStr;
while (*srcStrUb2++) ++srcLen;
srcLen *= sizeof(ub2);
}
else
srcLen = ACIMultiByteStrlen(envhp, srcStr);
checkerr(errhp,ACINlsCharSetConvert(envhp,errhp,ACI_UTF16ID,dstBuf, dstSize, cid, srcStr, srcLen, &dstLen));
return dstLen/sizeof(ub2);
}
绑定和定义字符数据¶
若要指定Unicode字符集来绑定和定义具有字符串数据类型的数据,您可能需要调用 ACIAttrSet 函数以在ACIBind()或ACIDefine()API之后设置适当的字符集ID。 有两种情况:
- 设置ACIBind和 ACIDefine句柄的ACI_ATTR_CHARSET_ID属性为UTF-16 Unicode字符集编码。 例如:
ub2 csid = ACI_UTF16ID;
utext ename[100];
...
ACIBindByName(stmthp1, &bnd1p, errhp, (oratext*)":ENAME",
(sb4)strlen((char *)":ENAME"), (void *) ename, sizeof(ename),
SQLT_STR, (void *)&insname_ind, (ub2 *) 0, (ub2 *) 0, (ub4) 0, (ub4 *)0, ACI_DEFAULT);
ACIAttrSet((void *) bnd1p, (ub4) ACI_HTYPE_BIND, (void *) &csid,
(ub4) 0, (ub4)ACI_ATTR_CHARSET_ID, errhp);
ACIAttrSet((void *) bnd1p, (ub4) ACI_HTYPE_BIND, (void *) &ename_col_len,
(ub4) 0, (ub4)ACI_ATTR_MAXDATA_SIZE, errhp);
...
ACIDefineByPos (stmthp2, &dfn1p, errhp, (ub4)1, (void *)ename,
(sb4)sizeof(ename), SQLT_STR, (void *)0, (ub2 *)0,
(ub2*)0, (ub4)ACI_DEFAULT);
ACIAttrSet((void *) dfn1p, (ub4) ACI_HTYPE_DEFINE, (void *) &csid,
(ub4) 0, (ub4)ACI_ATTR_CHARSET_ID, errhp);
如果绑定缓冲区是utext数据类型,则应在调用ACIBind或ACIDefine时添加强制转换(text * )。 ACI_ATTR_MAXDATA_SIZE属性的值通常由服务器字符集的列大小确定,因为在执行绑定操作时,此大小仅用于分配临时缓冲区空间以在服务器上进行转换。
- 设置NLS_OSCAR_LANG的俩设置ACIBind和ACIDefine字符集。
可以在NLS_OSCAR_LANG环境变量中设置UTF8或AL32UTF8。 调用ACIBind和ACIDefine的方式与不使用Unicode时完全相同。 将NLS_OSCAR_LANG环境变量设置为UTF8或AL32UTF8,然后运行以下ACI程序:
...
oratext ename[100];
...
ACIBindByName(stmthp1, &bnd1p, errhp, (oratext*)":ENAME",
(sb4)strlen((char *)":ENAME"), (void *) ename, sizeof(ename),
SQLT_STR, (void *)&insname_ind, (ub2 *) 0, (ub2 *) 0,
(ub4) 0, (ub4 *)0, ACI_DEFAULT);
ACIAttrSet((void *) bnd1p, (ub4) ACI_HTYPE_BIND, (void *) &ename_col_len,
(ub4) 0, (ub4)ACI_ATTR_MAXDATA_SIZE, errhp);
...
ACIDefineByPos (stmthp2, &dfn1p, errhp, (ub4)1, (void *)ename,
(sb4)sizeof(ename), SQLT_STR, (void *)0, (ub2 *)0, (ub2*)0,
(ub4)ACI_DEFAULT);
...
备注:CLOB的处理也类似,在LOB处理函数中需要进行对应处理。
ACI获取客户端字符集¶
您可以使用 ACINlsGetInfo 函数获得默认字符集
例如:
ssword MyPrintLinguisticName(envhp, errhp)
ACIEnv *envhp;
ACIError *errhp;
{
OraText infoBuf[20];
sword ret;
ret = ACINlsGetInfo(envhp, /*环境句柄 */
errhp, /* 错误句柄 */
infoBuf, /* 目标变量 */
20, /* 目标变量长度 */
(ub2) ACI_NLS_CHARACTER_SET); /* 信息项目 */
if (ret != ACI_SUCCESS)
{
checkerr(errhp, ret, ACI_HTYPE_ERROR);
ret = ACI_ERROR;
}
else
{
printf("charset name : %s\n", infoBuf);
}
return(ret);
}
ACI扩展宽字符类型¶
多字节字符串以本机字符集编码。对多字节字符串进行操作的函数将字符串作为一个整体,并以字节为单位计算字符串的长度。宽字符字符串(wchar)函数在字符串操作中提供了更大的灵活性。它们支持基于字符和基于字符串的操作,其中字符串的长度以字符为单位。
宽字符数据类型ACIWchar是ACI支持的自定义类型,不应与ANSI / ISO C标准定义的wchar_t数据类型混淆。在所有操作系统中,ACI宽字符数据类型始终为4个字节,而wchar_t的大小取决于实现和操作系统。 ACI宽字符数据类型对多字节字符进行规范化,以便它们具有统一的固定宽度,以便于处理。这样可以保证在Oracle宽字符集和本机字符集之间进行往返转换时不会丢失任何数据。
字符串操作可以分为以下几类:
- 多字节和宽字符之间的字符串转换
- 大小写转换
- 显示长度的计算
- 常规的字符串操作,例如比较,拼接和搜索
ACIWchar类型的使用示例:
size_t MyConvertMultiByteToWideChar(envhp, dstBuf, dstSize, srcStr)
ACIEnv *envhp;
ACIWchar *dstBuf;
size_t dstSize;
OraText *srcStr; /* 字符串数据*/
{
sword ret;
size_t dstLen = 0;
size_t srcLen;
/* 获得数据长度 */
srcLen = ACIMultiByteStrlen(envhp, srcStr);
ret = ACIMultiByteInSizeToWideChar(envhp, /* 环境句柄 */
dstBuf, /* 目标变量 */
dstSize, /* 目标变量长度 */
srcStr, /* 源字符串 */
srcLen, /* 源字符串长度 */
&dstLen); /* 返回目标变量中的数据长度 */
if (ret != ACI_SUCCESS)
{
checkerr(envhp, ret, ACI_HTYPE_ENV);
}
return(dstLen);
}
ACI字符长度语意¶
ACI充当服务器和客户端之间的翻译器,并传递字符信息以进行约束检查。
字符集有两种:可变宽度和固定宽度。 (单字节字符集是固定宽度字符集的一种特殊情况,其中每个字节代表一个字符。)
对于固定宽度的字符集,约束检查更容易,因为字节数等于字符数的倍数。 因此,不需要扫描整个字符串来确定固定宽度字符集的字符数。 但是,对于宽度可变的字符集,需要完全扫描以确定字符串中的字符数。
开发者注意事项¶
您可能遇到这种问题,导致数据库操作出错:
在Linux环境中,当程序文件编码为GBK,系统编码为UTF8,且 ACIEnvNlsCreate 的charset参是为0,也没有设置NLS_OSCAR_LANG环境变量的情况下,ACI误将GBK的数据当成UTF8进行数据转换,在转换过程中会程序错误或转换成乱码到数据库中。原因是ACI源码中的数据编码要与ACI的客户端字符集一致,在没有设置charset和NLS_OSCAR_LANG情况下,ACI获取了Linux的默认字符集为utf8,与文件的GBK字符集不一致,导致出错。
这种情况需要设置NLS_OSCAR_LANG=GBK,这样ACI会以GBK编码来解析输入和输出数据;或者 ACIEnvNlsCreate 的charset设置为854(GB18030)即可。
同理在Windows环境中,系统默认编码为GBK,如果程序文件的文件编码不是GBK,而是UTF8,则需要设置NLS_OSCAR_LANG=UTF8的环境变量,避免错误出现。